
Hi,
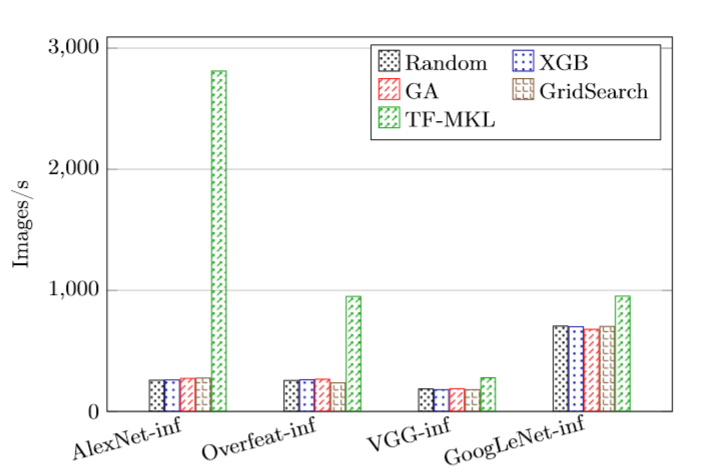
I’m running AutoTVM on Intel Xeon CascadeLake (Platinum 8280) with TVM target “llvm -mcpu=skylake-avx512”. The results I’m getting are in the following plot (4 different tuners) and in comparison to TF-MKL, I’m not sure why I’m getting bad results. I’m adding my AlexNet example to show how I’m setting up tuning jobs.
Any explanations on the following results are much appreciated.
I’m importing my workloads through relay.testing. The Alexnet version I’m using is here.
from tvm import relay
from .init import create_workload
from . import layers as wrapper
def get_net(batch_size, image_shape, num_classes, dtype, batch_norm=False):
data_shape = (batch_size,) + image_shape
data = relay.var("data", shape=data_shape, dtype=dtype)
feature = wrapper.conv2d(data=data, channels=64, kernel_size=(11,11), strides=(4,4), padding=(0,0), name="conv1")
feature = relay.nn.bias_add(feature, relay.var("conv1_bias"))
feature = relay.nn.relu(data=feature)
feature = relay.nn.max_pool2d(data=feature, pool_size=(5, 5), strides=(1, 1), padding=(2,2))
feature = wrapper.conv2d(data=feature, channels=192, kernel_size=(5,5), strides=(1,1), padding=(2,2), name="conv2")
feature = relay.nn.bias_add(feature, relay.var("conv2_bias"))
feature = relay.nn.relu(data=feature)
feature = relay.nn.max_pool2d(data=feature, pool_size=(3, 3), strides=(2, 2), padding=(0,0))
feature = wrapper.conv2d(data=feature, channels=384, kernel_size=(3,3), strides=(1,1), padding=(1,1), name="conv3")
feature = relay.nn.bias_add(feature, relay.var("conv3_bias"))
feature = relay.nn.relu(data=feature)
feature = wrapper.conv2d(data=feature, channels=384, kernel_size=(3,3), strides=(1,1), padding=(1,1), name="conv4")
feature = relay.nn.bias_add(feature, relay.var("conv4_bias"))
feature = relay.nn.relu(data=feature)
feature = wrapper.conv2d(data=feature, channels=256, kernel_size=(3,3), strides=(1,1), padding=(1,1), name="conv5")
feature = relay.nn.bias_add(feature, relay.var("conv5_bias"))
feature = relay.nn.relu(data=feature)
feature = relay.nn.max_pool2d(data=feature, pool_size=(3, 3), strides=(2, 2), padding=(0,0))
flatten = relay.nn.batch_flatten(data=feature)
fc6 = wrapper.dense_add_bias(data=flatten, units=4096, name="fc6")
fc7 = wrapper.dense_add_bias(data=fc6, units=4096, name="fc7")
fc8 = wrapper.dense_add_bias(data=fc7, units=num_classes, name="fc8")
#symbol = relay.nn.softmax(data=fc8)
args = relay.analysis.free_vars(fc8)
return relay.Function(args, fc8)
def get_workload(batch_size,
num_classes=1008,
image_shape=(3, 227, 227),
dtype="float32",
batch_norm=False):
net = get_net(batch_size, image_shape, num_classes, dtype)
return create_workload(net)
And the test harness I’m running is based on tune_relay_x86.py tutorial.
import os
import numpy as np
import tvm
from tvm import autotvm
from tvm import relay
from tvm.relay import testing
from tvm.autotvm.tuner import XGBTuner, GATuner, RandomTuner, GridSearchTuner
from tvm.autotvm.graph_tuner import DPTuner, PBQPTuner
import tvm.contrib.graph_runtime as runtime
def get_network(name, batch_size):
if name == 'alexnet':
input_shape = (128, 3, 227, 227)
output_shape = (128, 1008)
mod, params = relay.testing.alexnet1.get_workload(128, 1008)
else:
raise ValueError("Unsupported network: " + name)
return mod, params, input_shape, output_shape
target = "llvm -mcpu=skylake-avx512"
batch_size = 128
dtype = "float32"
model_name = "alexnet"
log_file = "%s.log" % model_name
graph_opt_sch_file = "%s_graph_opt.log" % model_name
input_name = "data"
num_threads = 56
os.environ["TVM_NUM_THREADS"] = str(num_threads)
tuning_option = {
'log_filename': log_file,
'tuner': 'random',
'early_stopping': None,
'measure_option': autotvm.measure_option(
builder=autotvm.LocalBuilder(),
runner=autotvm.LocalRunner(number=10, repeat=1,
min_repeat_ms=1000, timeout=1000),
),
}
def tune_kernels(tasks,
measure_option,
tuner='gridsearch',
early_stopping=None,
log_filename='tuning.log'):
for i, tsk in enumerate(tasks):
prefix = "[Task %2d/%2d] " % (i+1, len(tasks))
# converting conv2d tasks to conv2d_NCHWc tasks
op_name = tsk.workload[0]
if op_name == 'conv2d':
func_create = 'topi_x86_conv2d_NCHWc'
elif op_name == 'depthwise_conv2d_nchw':
func_create = 'topi_x86_depthwise_conv2d_NCHWc_from_nchw'
else:
raise ValueError("Tuning {} is not supported on x86".format(op_name))
task = autotvm.task.create(func_create, args=tsk.args,
target=target, template_key='direct')
task.workload = tsk.workload
# create tuner
if tuner == 'xgb' or tuner == 'xgb-rank':
tuner_obj = XGBTuner(task, loss_type='rank')
elif tuner == 'ga':
tuner_obj = GATuner(task, pop_size=50)
elif tuner == 'random':
tuner_obj = RandomTuner(task)
elif tuner == 'gridsearch':
tuner_obj = GridSearchTuner(task)
else:
raise ValueError("Invalid tuner: " + tuner)
# do tuning
n_trial=len(task.config_space)
tuner_obj.tune(n_trial=n_trial,
early_stopping=early_stopping,
measure_option=measure_option,
callbacks=[
autotvm.callback.progress_bar(n_trial, prefix=prefix),
autotvm.callback.log_to_file(log_filename)])
def tune_graph(graph, dshape, records, opt_sch_file, use_DP=True):
target_op = [relay.nn.conv2d]
Tuner = DPTuner if use_DP else PBQPTuner
executor = Tuner(graph, {input_name: dshape}, records, target_op, target)
executor.benchmark_layout_transform(min_exec_num=100, timeout=10)
executor.run()
executor.write_opt_sch2record_file(opt_sch_file)
def tune_and_evaluate(tuning_opt):
# extract workloads from relay program
print("Extract tasks...")
mod, params, data_shape, out_shape = get_network(model_name, batch_size)
tasks = autotvm.task.extract_from_program(mod["main"], target=target,
params=params, ops=(relay.op.nn.conv2d,))
# run tuning tasks
print("Tuning...")
tune_kernels(tasks, **tuning_opt)
tune_graph(mod["main"], data_shape, log_file, graph_opt_sch_file)
# compile kernels with graph-level best records
with autotvm.apply_graph_best(graph_opt_sch_file):
print("Compile...")
with relay.build_config(opt_level=3):
graph, lib, params = relay.build_module.build(
mod, target=target, params=params)
# upload parameters to device
ctx = tvm.cpu()
data_tvm = tvm.nd.array((np.random.uniform(size=data_shape)).astype(dtype))
module = runtime.create(graph, lib, ctx)
module.set_input(input_name, data_tvm)
module.set_input(**params)
# evaluate
print("Evaluate inference time cost...")
ftimer = module.module.time_evaluator("run", ctx, number=1000, repeat=1)
prof_res = np.array(ftimer().results)
print("Mean inference time (std dev): %.2f ms (%.2f ms)" %
(np.mean(prof_res), np.std(prof_res)))
print("Network Throughput: %.2f imgs/s" %(batch_size/np.mean(prof_res)))
tune_and_evaluate(tuning_option)
Thanks,