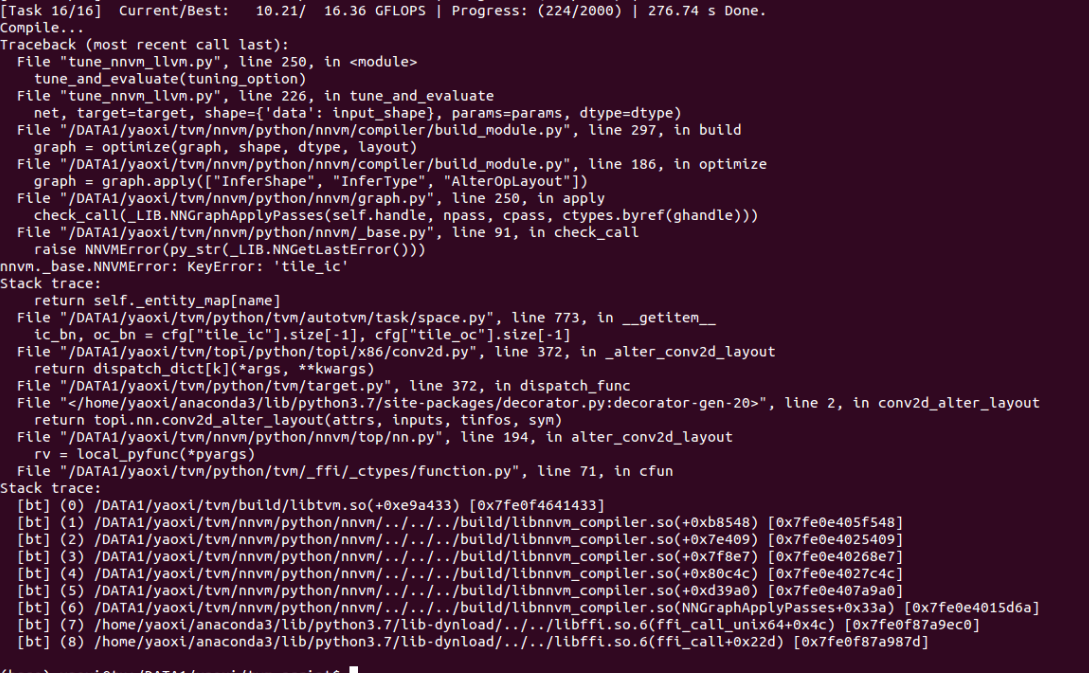
The following applies to tag v0.4 of the tvm repository on a NXP i.MX8M EVK target.
After successful auto-tuning of a mobilefacenet network, I encountered the following error upon compilation. The input neural network is from the the files model-symbol.json and model-0000.params found at the github repository at https://github.com/honghuCode/mobileFacenet-ncnn. The run script which encountered the error is listed below the error message.
Compile…
LLVM ERROR: Cannot select: 0x5632afc435a0: i32 = any_extend 0x5632af6e4b40
0x5632af6e4b40: v8i8 = AArch64ISD::UZP1 0x5632af6e4db0, 0x5632afc434d0
0x5632af6e4db0: v8i8 = bitcast 0x5632afc43260
0x5632afc43260: v4i16 = truncate 0x5632afc43a80
0x5632afc43a80: v4i32 = AArch64ISD::FCMGTz 0x5632af6e4ee8
0x5632af6e4ee8: v4f32 = fma 0x5632aff4da70, 0x5632aff22738, 0x5632b08c20f8
0x5632aff4da70: v4f32,ch = CopyFromReg 0x5632af121b20, Register:v4f32 %76
0x5632aff22808: v4f32 = Register %76
0x5632aff22738: v4f32,ch = CopyFromReg 0x5632af121b20, Register:v4f32 %15
0x5632b08c2028: v4f32 = Register %15
0x5632b08c20f8: v4f32,ch = CopyFromReg 0x5632af121b20, Register:v4f32 %17
0x5632b08c2160: v4f32 = Register %17
0x5632afc434d0: v8i8 = bitcast 0x5632aff4ddb0
0x5632aff4ddb0: v4i16 = truncate 0x5632afc43330
0x5632afc43330: v4i32 = AArch64ISD::FCMGTz 0x5632b0513188
0x5632b0513188: v4f32 = fma 0x5632af6e5500, 0x5632aff226d0, 0x5632b08c2090
0x5632af6e5500: v4f32,ch = CopyFromReg 0x5632aff4da70:1, Register:v4f32 %77
0x5632aff4d250: v4f32 = Register %77
0x5632aff226d0: v4f32,ch = CopyFromReg 0x5632aff22738:1, Register:v4f32 %16
0x5632aff219d0: v4f32 = Register %16
0x5632b08c2090: v4f32,ch = CopyFromReg 0x5632b08c20f8:1, Register:v4f32 %18
0x5632b0513940: v4f32 = Register %18
In function: __tvm_parallel_lambda.73
-------- Run Script --------------------------------------------------------------------------------------------
import os
import numpy as np
import nnvm.testing
import nnvm.compiler
import tvm
from tvm import autotvm
from tvm.autotvm.tuner import XGBTuner, GATuner, RandomTuner, GridSearchTuner
from tvm.contrib.util import tempdir
import tvm.contrib.graph_runtime as runtime
import mxnet as mx
import inspect
#symbolTpl= (‘abs’, ‘argmax’, ‘argmin’, ‘avg_pool2d’, ‘batch_norm’, ‘block_grad’, ‘broadcast_add’, ‘broadcast_div’, ‘broadcast_equal’, ‘broadcast_greater’, ‘broadcast_greater_equal’, ‘broadcast_left_shift’, ‘broadcast_less’, ‘broadcast_less_equal’, ‘broadcast_max’, ‘broadcast_min’, ‘broadcast_mod’, ‘broadcast_mul’, ‘broadcast_not_equal’, ‘broadcast_pow’, ‘broadcast_right_shift’, ‘broadcast_sub’, ‘broadcast_to’, ‘cast’, ‘ceil’, ‘clip’, ‘collapse_sum’, ‘concatenate’, ‘contrib’, ‘conv2d’, ‘conv2d_transpose’, ‘copy’, ‘dense’, ‘dropout’, ‘elemwise_add’, ‘elemwise_div’, ‘elemwise_mod’, ‘elemwise_mul’, ‘elemwise_pow’, ‘elemwise_sub’, ‘elemwise_sum’, ‘exp’, ‘expand_dims’, ‘expand_like’, ‘flatten’, ‘flip’, ‘floor’, ‘full’, ‘full_like’, ‘global_avg_pool2d’, ‘global_max_pool2d’, ‘greater’, ‘l2_normalize’, ‘leaky_relu’, ‘less’, ‘log’, ‘log_softmax’, ‘lrn’, ‘matmul’, ‘max’, ‘max_pool2d’, ‘mean’, ‘min’, ‘multibox_prior’, ‘multibox_transform_loc’, ‘negative’, ‘nms’, ‘np’, ‘ones’, ‘ones_like’, ‘pad’, ‘prelu’, ‘prod’, ‘relu’, ‘reshape’, ‘reshape_like’, ‘resize’, ‘round’, ‘sigmoid’, ‘slice_like’, ‘softmax’, ‘split’, ‘sqrt’, ‘squeeze’, ‘strided_slice’, ‘sum’, ‘take’, ‘tanh’, ‘transpose’, ‘trunc’, ‘tvm_op’, ‘upsampling’, ‘where’, ‘yolo_region’, ‘yolo_reorg’, ‘yolov3_yolo’, ‘zeros’, ‘zeros_like’)
symbolList = []
for i in inspect.getmembers(nnvm.sym):
if not i[0].startswith(’_’) and not inspect.ismethod(i[1]):
if not i[0].startswith(’_’) and inspect.isfunction(i[1]):
symbolList.append(i[0])
#raw_input(“After Imports”)
target = tvm.target.create(‘llvm -device=arm_cpu -target=aarch64-linux-gnu’)
#target = tvm.target.create(‘llvm -device=intel_cpu -target=x86-64-linux-gnu’)
device_key = ‘imx8m’
use_android = False
def get_network(name, batch_size):
“”“Get the symbol definition and random weight of a network”""
input_shape = (batch_size, 3, 112, 112)
output_shape = (batch_size, 1000)
mx_sym, args, auxs = mx.model.load_checkpoint(‘model’, 0)
net, params = nnvm.frontend.from_mxnet(mx_sym, args, auxs)
onnx_model = onnx.load_model(‘super_resolution.onnx’)
# we can load the graph as NNVM compatible model
sym, params = nnvm.frontend.from_onnx(onnx_model)
input_name = sym.list_input_names()[0]
shape_dict = {input_name: x.shape}
sym, params = nnvm.frontend.from_mxnet(block)
# we want a probability so add a softmax operator
sym = nnvm.sym.softmax(sym)
return net, params, input_shape, output_shape
TUNING OPTION
network = ‘model’
log_file = “%s.%s.log” % (device_key, network)
dtype = ‘float32’
tuning_option = {
‘log_filename’: log_file,
‘tuner’: ‘xgb’,
‘n_trial’: 1000,
‘n_trial’: 2000,
‘early_stopping’: 400,
‘early_stopping’: 500,
‘measure_option’: autotvm.measure_option(
builder=autotvm.LocalBuilder(
build_func=‘ndk’ if use_android else ‘default’),
runner=autotvm.RPCRunner(
device_key, host=‘localhost’, port=9190,
number=5,
timeout=4,
),
),
‘measure_option’: autotvm.measure_option(
autotvm.measure.rpc(device_key, host=‘localhost’, port=9190),
number=4,
n_parallel=1,
timeout=10,
build_func=‘ndk’ if use_android else ‘default’,
),
}
def tune_tasks(tasks,
measure_option,
tuner=‘xgb’,
n_trial=1000,
early_stopping=None,
log_filename=‘tuning.log’,
use_transfer_learning=True,
try_winograd=True):
if try_winograd:
for i in range(len(tasks)):
try: # try winograd template
tsk = autotvm.task.create(tasks[i].name, tasks[i].args,
tasks[i].target, tasks[i].target_host, ‘winograd’)
input_channel = tsk.workload[1][1]
if input_channel >= 64:
tasks[i] = tsk
except Exception:
pass
create tmp log file
tmp_log_file = log_filename + “.tmp”
if os.path.exists(tmp_log_file):
os.remove(tmp_log_file)
for i, tsk in enumerate(reversed(tasks)):
prefix = "[Task %2d/%2d] " % (i+1, len(tasks))
# create tuner
if tuner == 'xgb' or tuner == 'xgb-rank':
tuner_obj = XGBTuner(tsk, loss_type='rank')
elif tuner == 'ga':
tuner_obj = GATuner(tsk, pop_size=50)
elif tuner == 'random':
tuner_obj = RandomTuner(tsk)
elif tuner == 'gridsearch':
tuner_obj = GridSearchTuner(tsk)
else:
raise ValueError("Invalid tuner: " + tuner)
if use_transfer_learning:
# if os.path.isfile(tmp_log_file):
# tuner_obj.load_history(autotvm.record.load_from_file(tmp_log_fil
# e))
if os.path.isfile(log_file):
tuner_obj.load_history(autotvm.record.load_from_file(log_file))
# do tuning
tuner_obj.tune(n_trial=min(n_trial, len(tsk.config_space)),
early_stopping=early_stopping,
measure_option=measure_option,
callbacks=[
autotvm.callback.progress_bar(n_trial, prefix=prefix),
autotvm.callback.log_to_file(tmp_log_file)])
pick best records to a cache file
autotvm.record.pick_best(tmp_log_file, log_filename)
os.remove(tmp_log_file)
def tune_and_evaluate(tuning_opt):
extract workloads from nnvm graph
print(“Extract tasks…”)
net, params, input_shape, out_shape = get_network(network, batch_size=1)
#tgraph,tish,tidt,tosh,todt = nnvm.testing.check_computation.infer_shapes_dtypes(net)
#print(“Input Shape: {}”.format(tish))
tasks = autotvm.task.extract_from_graph(net, target=target,
shape={‘data’: input_shape}, dtype=dtype,
symbols=(nnvm.sym.conv2d,))
symbols=[“nnvm.sym.{}”.format(y) for y in symbolList])
symbols=(nnvm.sym.conv2d,nnvm.sym.prelu))
symbols=(nnvm.sym.conv2d,))
run tuning tasks
print(“Tuning…”)
tune_tasks(tasks, **tuning_opt)
compile kernels with history best records
with autotvm.apply_history_best(log_file):
print(“Compile…”)
with nnvm.compiler.build_config(opt_level=3):
graph, lib, params = nnvm.compiler.build(
net, target=target, shape={‘data’: input_shape}, params=params, dtype=dtype)
# export library
tmp = tempdir()
if use_android:
from tvm.contrib import ndk
filename = "net.so"
lib.export_library(tmp.relpath(filename), ndk.create_shared)
else:
filename = "net.tar"
lib.export_library(tmp.relpath(filename))
# upload module to device
print("Upload...")
remote = autotvm.measure.request_remote(device_key, 'localhost', 9190,
timeout=10000)
remote.upload(tmp.relpath(filename))
rlib = remote.load_module(filename)
# upload parameters to device
ctx = remote.context(str(target), 0)
print("target: %s, ctx: %s" % (target,ctx))
#raw_input("After remote.context")
module = runtime.create(graph, rlib, ctx)
#raw_input("After runtime.create")
data_tvm = tvm.nd.array((np.random.uniform(size=input_shape)).astype(dtype))
module.set_input('data', data_tvm)
module.set_input(**params)
# evaluate
print("Evaluate inference time cost...")
ftimer = module.module.time_evaluator("run", ctx, number=8, repeat=3)
prof_res = np.array(ftimer().results) * 1000 # convert to millisecond
print("Mean inference time (std dev): %.2f ms (%.2f ms)" %
(np.mean(prof_res), np.std(prof_res)))
tune_and_evaluate(tuning_option)