Currently, there is an IR pass to combine parallel Conv2D ops. This is a kind of fusion strategy that reduces the number of kernels launched, improves data locality for those kernels, and reduces latency.
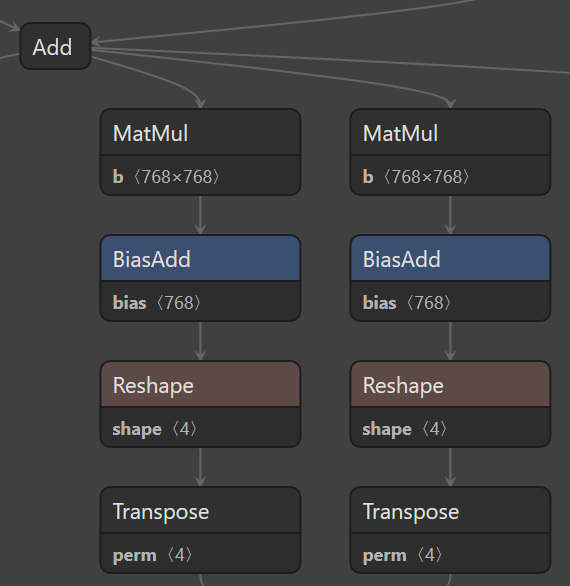
Models like BERT start each layer with three parallel branches that all utilize the same input and have the same sequence of operations. These branches start with a matmul op. By fusing theese matmuls, we can go from three sequential matrix multiplications of size (128,768) x (768,768) to one batch matrix multiplication of size (3,128,768) x (3,768,768). On GPU and multi-core CPU, this should provide significant speedup.
I propose to make an IR pass called CombineParallelDense, which will combine parallel Dense ops into one BatchMatMul op. This will be optionally followed by a single batch Add op if the “units” parameter of Dense is not null. This combine can be done in a very similar way to CombineParallelConv2D, and can even fuse the element-wise operations following it.
What do you think? How do you think the implementation should look so we don’t have to copy code between the two “combine” passes?
Here are two of the parallel branches that use the same input (the third branch is very far to the right in Netron, so it’s not shown here  )
)