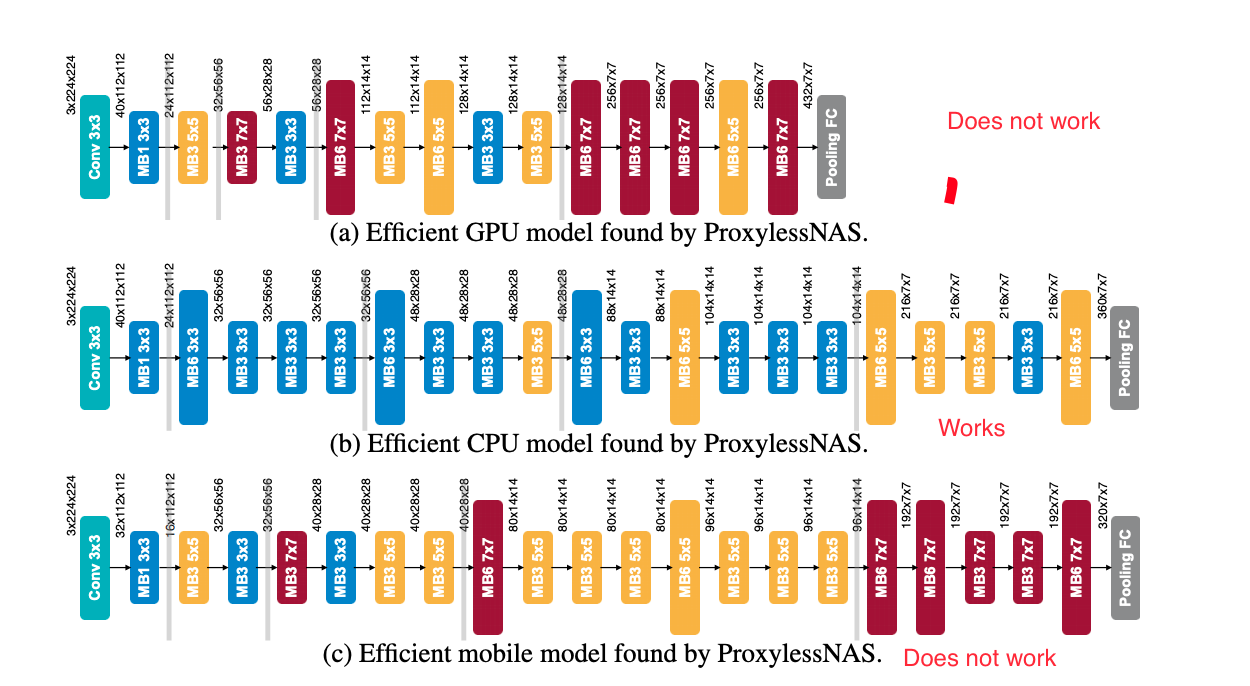
Hi there,
When I was trying to execute ProxylessNAS on CUDA devices, following the pipeline PyTorch -> ONNX -> TVM, I met following errors with cuda error code CUDA_ERROR_INVALID_PTX
Testing proxyless_net1
Exception occurs:
Traceback (most recent call last):
[bt] (3) /home/yaoyao/miniconda3/envs/python37/lib/python3.7/site-packages/tvm-0.6.dev0-py3.7-linux-x86_64.egg/tvm/libtvm.so(TVMFuncCall+0x65) [0x7f5f53b04ff5]
[bt] (2) /home/yaoyao/miniconda3/envs/python37/lib/python3.7/site-packages/tvm-0.6.dev0-py3.7-linux-x86_64.egg/tvm/libtvm.so(std::_Function_handler<void (tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*), tvm::runtime::detail::PackFuncVoidAddr_<4, tvm::runtime::CUDAWrappedFunc>(tvm::runtime::CUDAWrappedFunc, std::vector<tvm::runtime::detail::ArgConvertCode, std::allocator<tvm::runtime::detail::ArgConvertCode> > const&)::{lambda(tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*)#1}>::_M_invoke(std::_Any_data const&, tvm::runtime::TVMArgs&&, tvm::runtime::TVMRetValue*&&)+0xb6) [0x7f5f53b81fb6]
[bt] (1) /home/yaoyao/miniconda3/envs/python37/lib/python3.7/site-packages/tvm-0.6.dev0-py3.7-linux-x86_64.egg/tvm/libtvm.so(tvm::runtime::CUDAWrappedFunc::operator()(tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*, void**) const+0x832) [0x7f5f53b81e32]
[bt] (0) /home/yaoyao/miniconda3/envs/python37/lib/python3.7/site-packages/tvm-0.6.dev0-py3.7-linux-x86_64.egg/tvm/libtvm.so(dmlc::LogMessageFatal::~LogMessageFatal()+0x43) [0x7f5f533c2a33]
File "/home/yaoyao/repos/tvm/src/runtime/cuda/cuda_module.cc", line 111
File "/home/yaoyao/repos/tvm/src/runtime/module_util.cc", line 73
CUDAError: Check failed: ret == 0 (-1 vs. 0) : cuModuleLoadData(&(module_[device_id]), data_.c_str()) failed with error: CUDA_ERROR_INVALID_PTX
Testing proxyless_net2
Successfully.
After looking around, CUDA_ERROR_INVALID_PTX hints the problem might be related with PTX JIT compiler. However, the tvm runtime works well when I load the ResNet from torchvision. Could you help on this?
The code to re-produce is attached on Github and the environment we are using is
- GPU: Nvidia GTX 1080
- TVM: latest commit
45878ff2ab111b55448cf62e34bc58eb3e36b671 - CUDA: 10.1
- CUDNN: 7.0