
I think it is worthwhile to have a high-level quantization post explaining the flow and mentioning developers who are involved in different steps. This should improve collaboration, while also putting a high-level story to anybody who wants to explore TVM for quantization.
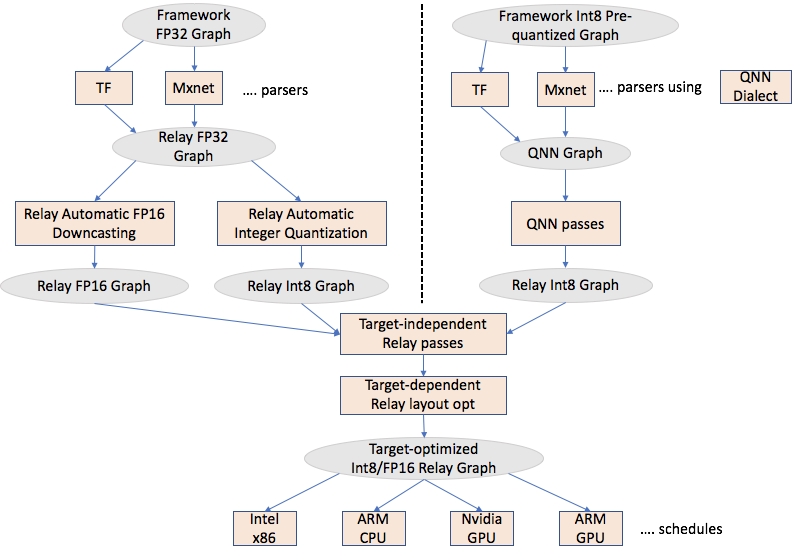
Frameworks to Relay
As shown in the above figure, there are two different parallel efforts ongoing
- Automatic Integer Quantization (@ziheng, @vinx13) - It takes a FP32 framework graph and automatically converts it to Int8 within Relay.
- Accepting Pre-quantized Integer models (@janimesh, @shoubhik) - This approach accepts a pre-quantized model, introduces a Relay dialect called QNN and generates an Int8 Relay graph.
There are few discussions around Relay Automatic FP16 Downcasting. There has not been any RFC yet. @xyzhou and @janimesh are exploring/prototyping this and plan to put up a RFC in next couple of weeks.
Relay Optimizations
- Target-independent Relay passes - TVM community is continuously adding these passes. Examples are fuse constant, common subexpression elimination etc.
- Target-dependent Relay passes - These passes transform the Relay graph to optimize it for the target. An example is Legalize or AlterOpLayout transform, where depending on the target, we change the layouts of convolution/dense layer. TVM community is working on improving on both infrastructure to enable such transformation, and adding target-specific layout transformations. Some of this infrastructure work is pre-requisite for a good overall design (https://github.com/dmlc/tvm/issues/3670).
Relay to Hardware
Once we have an optimized Relay graph, we need to write optimized schedules. Like FP32, we have to focus our efforts only on expensive ops like conv2d, dense etc. There are scattered efforts and TVM community is working on unifying them. Some of the developers that have worked on different backends (not necessarily Int8)
- Intel x86 - Near future Int8 exploration is restricted to Skylake and Cascade lake (@janimesh, @yzhliu, @kevinthesun)
- ARM - Some NHWC work going on currently for FP32. The plan is to extend this work to Int8 after FP32 work is finished (@jackwish, @FrozenGene, @thierry)
- Nvidia - @vinx13
Others who are interested/heavily involved - tqchen, zhiics, ramana-arm, yzhliu