
In the How to optimize GEMM on CPU tutorial’s Array Packing section, there is a picture:
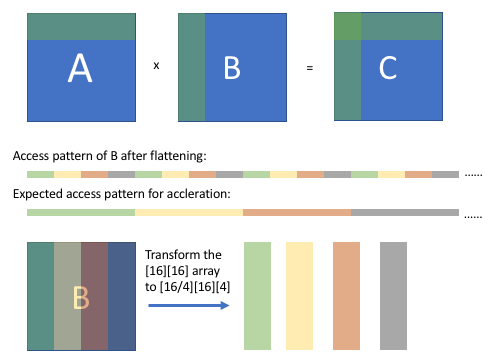
I think it wants to transform matrix B to store by column instead of storing by row, but why the tutorial reorder a [16][16] array to a [16/4][16][4] array? I don’t get it and want to get some help from you, thank you ~