
when I auto tune a modified mobilefacenet, I encountered the following error
if I use mxnet to inference, the time is 41ms. when I use apply_history_best(“model.log”) the time is 360ms.
if I just use relay.build without autotvm, the time is 390ms. it is so weird.
Did you set appropriate llvm target?
yes, target = tvm.target.create(“llvm -mcpu=core-avx2”)
if i use gpu, target = “cuda”, the time is 5ms.
when i build with opt_level=1 or opt_level=2, the time is 130ms. opt_level=3 is 390ms
link: https://pan.baidu.com/s/1HJnYdgt7aYoC1jwub3GaMw
code: bjys
this is the model, you can check it if you have time. or can you tell me how to find out the problem.
You can use debug_runtime to see whether conv2d execution takes majority of the time.
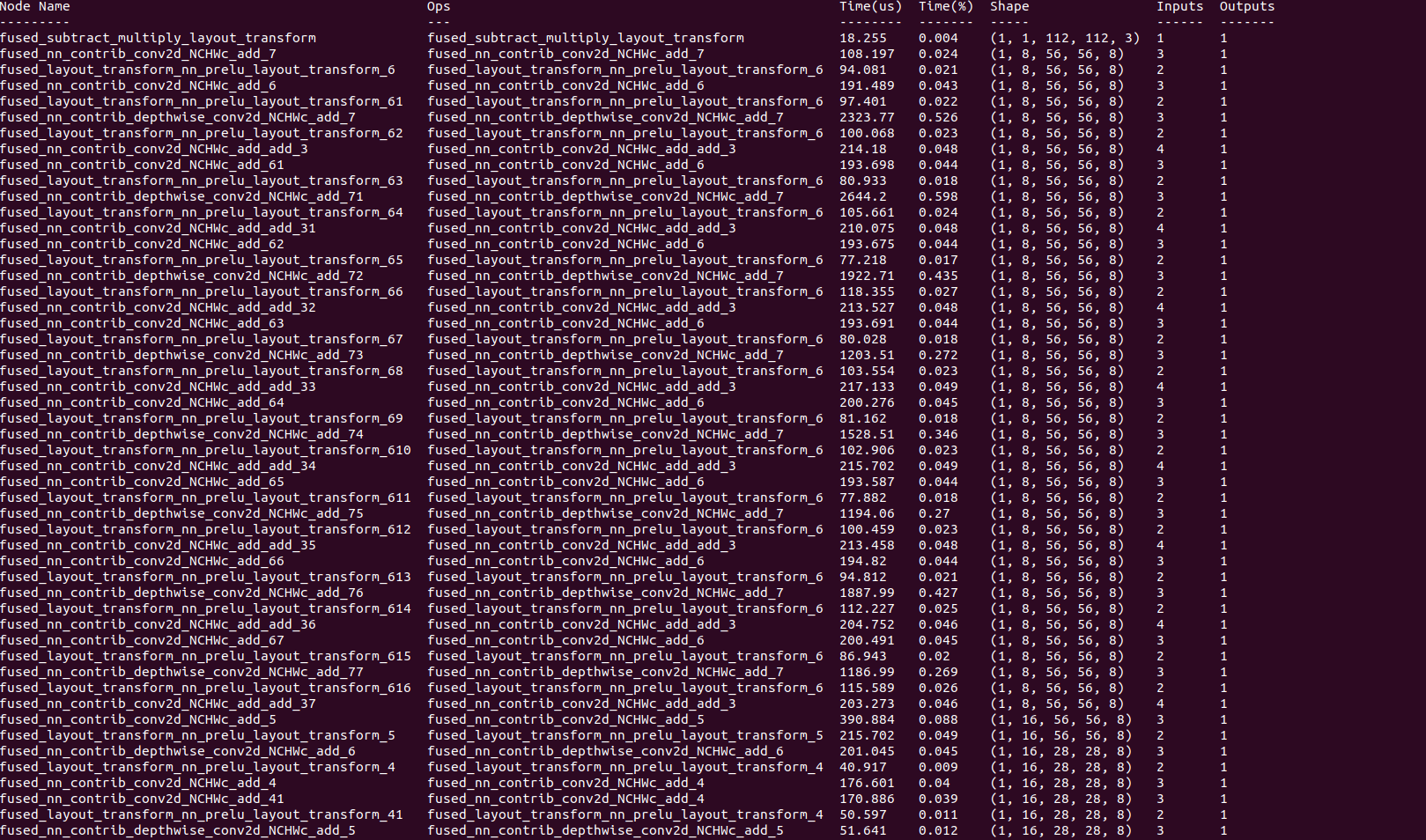
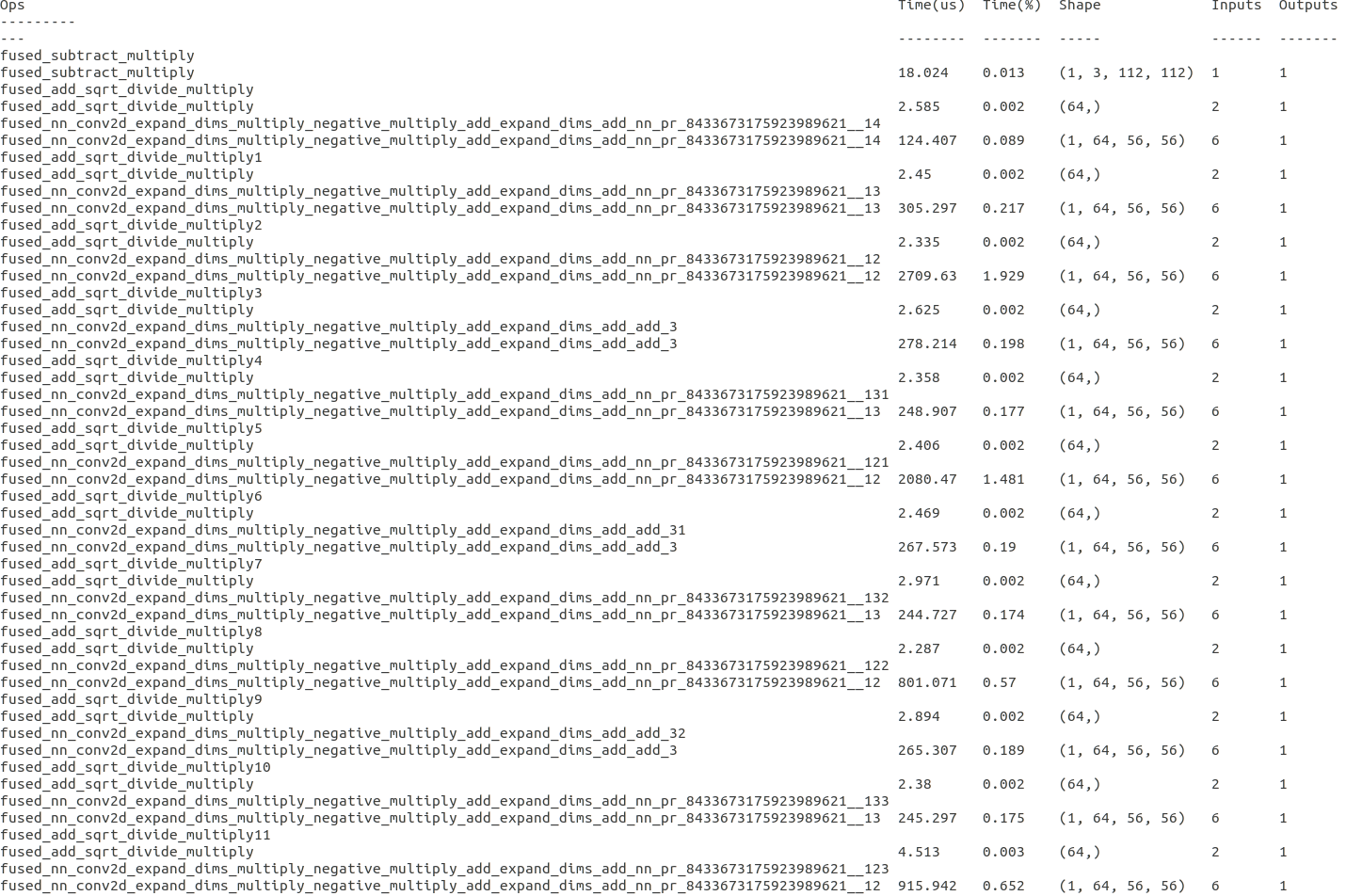
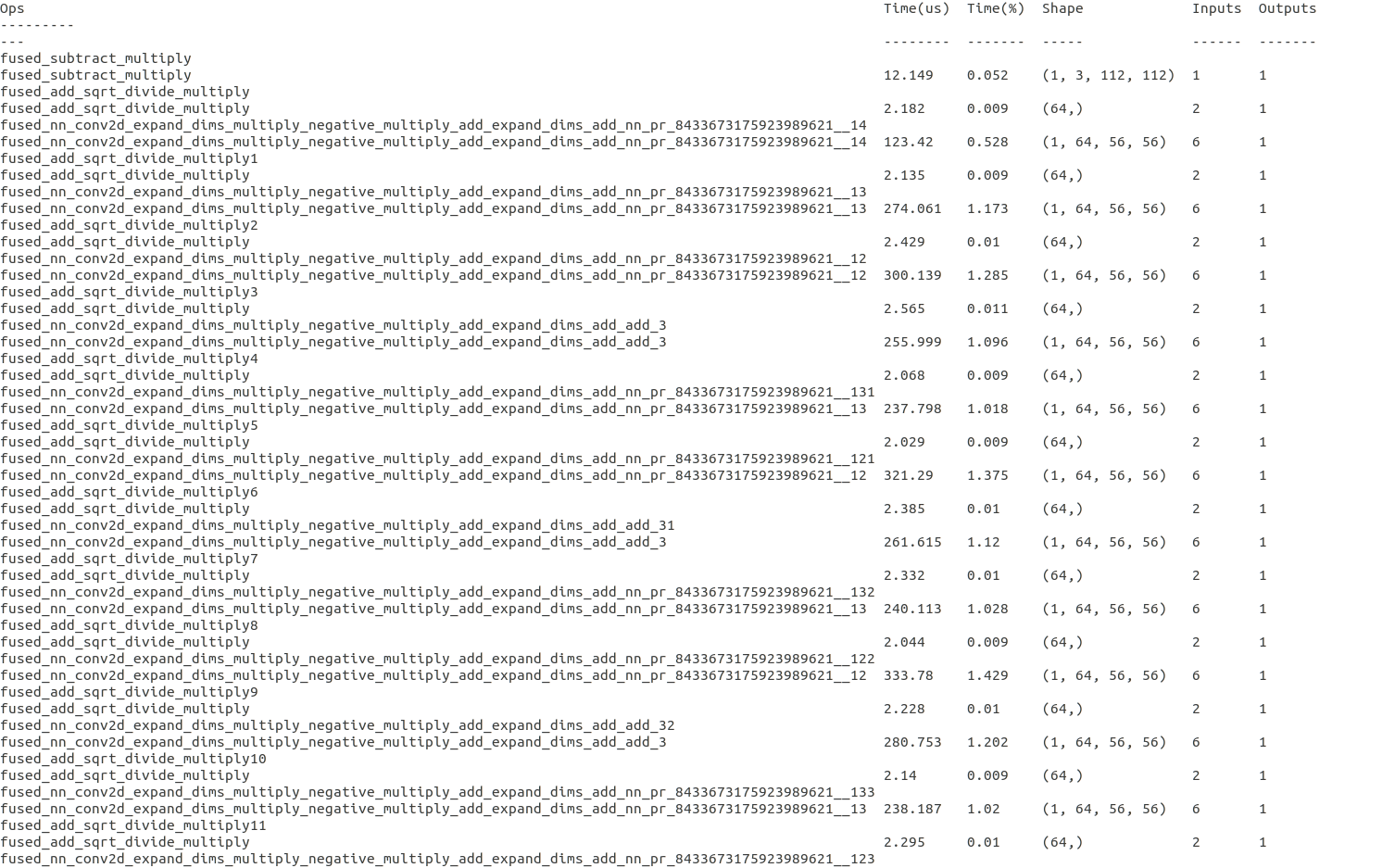

I have the same time problem when deploy r100 model, time is 700ms when I set opt_level=3, time is 220ms when opt_level=1. Can you have a look at this problem? @kevinthesun @tqchen
When setting opt_level=1, there is no depthwise-conv2d in the debug output. Can you look into this?
there is no depthwise-conv2d in the debug output using ori mobilefacenet, but In modified mobilefacenet there is depthwise-conv2d. The ori mobilefacenet is ok for opt_level=3 and work well using graph tuner. The modified mobilefacenet is not ok.
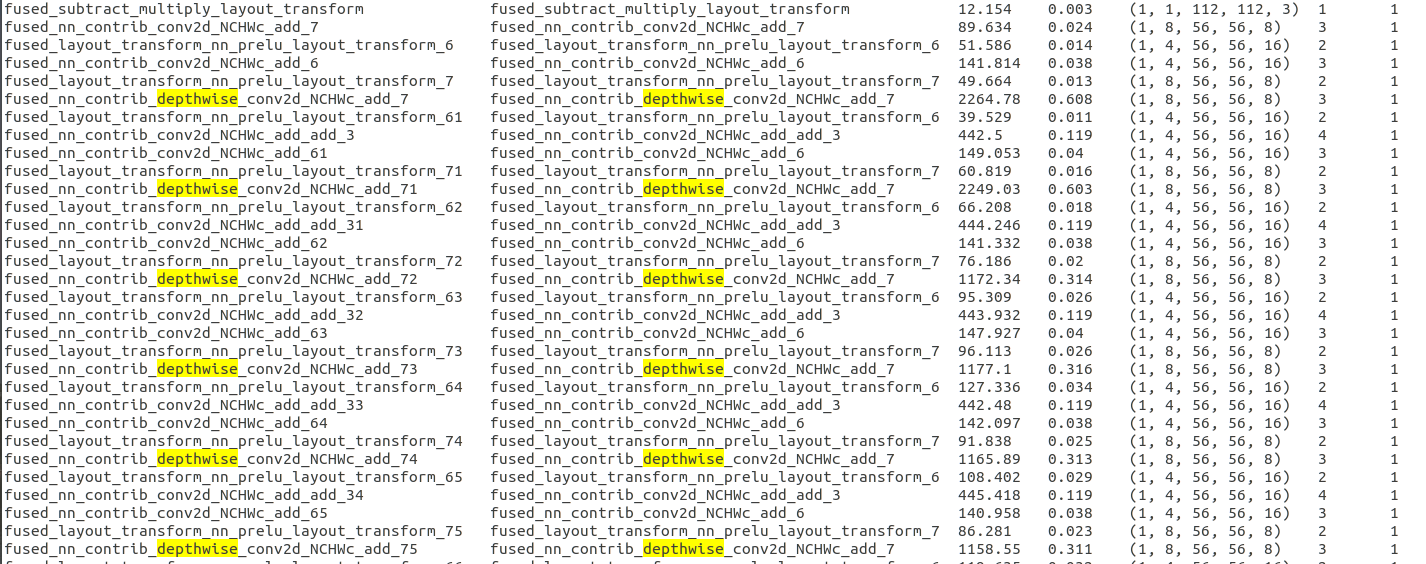
I have exactly the same problem. If opt_level=3 inference time is more than 2x slower than with opt_level=1.
1 Like