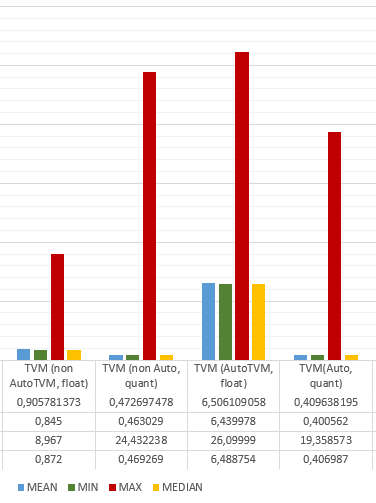
Hi there, I tried to benchmark multiple deep learning compilers on the raspberry pi 4. For most of them I compiled them into standalone bundles. But I was unable to achieve this with TVM after Auto-Tuning or Quantization (do not know why).
But I was told, that I should use the remote runtime module time_evaluator function. Problem is: The output is 10x higher than what has been measured previously.
In the standalones only the raw inference time has been measured and from the documentation of TVM it looks like, that should be the case for the runtime as well. But I get 6ms instead 0.8ms per inference.
I found the Issue on GitHub, which seems to address wrong time_evaluator outputs, but ARM CPUs should be fixed and the problem was to small outputs. (https://github.com/apache/incubator-tvm/issues/5215)
Why is the result so different? And is there a way to deploy to standalone without the runtime? (see AutoTVM or Quantization for Raspberry Pi fails)