update (March 3, 2021): The integration is finished, see our blog post
Motivation
The current autotvm requires pre-defined schedule templates. This makes autotvm only semi-automated: the search is automated, but the search space has to be manually defined by developers using the schedule templates. This approach has several drawbacks:
- The templates are hard to write. It takes a great number of engineering efforts to develop these templates.
- The number of required templates is large and continues to grow as new operators come.
- The templates are far from optimal. There is still huge opportunity for performance improvements by enlarging the search space in templates, but manually enumerating these optimizations choices is prohibitive.
Our solution
We implemented Ansor, a new framework to replace the existing autotvm. Ansor has several key advantages:
- Ansor automatically generates a much larger search space from compute declaration only
- Ansor searches more efficiently than AutoTVM by utilizing improved cost model, evolutionary search and task scheduler
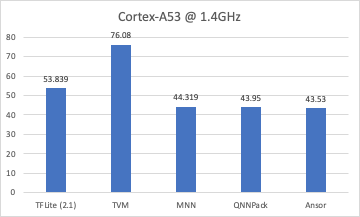
We have got good results on a variety of deep learning models (ResNet, MobileNet, 3D-ResNet, DCGAN, BERT) and hardware platforms (Intel CPU, NVIDIA GPU, ARM CPU). Ansor outperforms autotvm on all benchmarks with significant speedup. Please see our tech report for more details.
In terms of implementations, there are several major components of Ansor:
- The infrastructure for search: A new lightweight loop structure IR to enable flexible and efficient loop manipulation.
- The search policy and new cost model
- Relay integration
They are mainly implemented in C++ with around 10K lines of code. We plan to gradually upstream them for ease of review.
Integration Process
We will upstream our code with several pull requests and then deprecate autotvm. The steps are:
- Upstream the infrastructure for search (i.e. the lightweight loop structure IR)
- Upstream search policy and tutorials for auto-scheduling an operator or a subgraph
- Upstream relay integration and tutorials for auto-scheduling a network
- Design customization APIs to support customized search space
- Deprecate autotvm
Our code is almost ready and we will send the first PR in the next week.
This is joint work with @jcf94 @MinminSun @FrozenGene @comaniac @yangjunpro @yidawang
Any feedback on the design, tech report, and integration is welcomed.