@tqchen @thierry @liangfu @hjiang @vegaluis
All the features proposed have been implemented. Do you have any other comments/concerns? Is it ok that we proceed with a formal RFC and PR?
Thanks.

@tqchen @thierry @liangfu @hjiang @vegaluis
All the features proposed have been implemented. Do you have any other comments/concerns? Is it ok that we proceed with a formal RFC and PR?
Thanks.
Thank you @zhanghaohit, @remotego, @liangfu, @hjiang for the discussion.
This is a great step forward for VTA. Having a story for PCI-E type FPGAs is highly needed and has been a little too overlooked lately, so I appreciate the solid RFC and the hard work. The TVM community looks forward to your PRs!
Before addressing the low level engineering details I wanted to take a step back to look at VTA today. Currently VTA is a collection of sources that follow an accelerator design defined by its low-level (microcode) and task-level ISA. As such there is a collection of sources that have been maintained that need to align functionally:
Finally, we’re proposing a 4th design entry method which would leverage OpenCL programming language. In terms of pros, OpenCL is adopted by both Intel and Xilinx as a programming language for its FPGAs (minus several vendor specific pragmas). It can target both PCI-E based and SoC type designs. As a negative, it is difficult to expose virtual threads in the design, so we may lose the benefit of virtual threading in those designs, but it makes the compilation story a little cleaner, easier to maintain.
So the high level question on VTA is: given that we’re introducing more design entries for VTA, how are we going to make sure that they follow the same spec, and don’t bitrot/feature drift over time? And if they don’t follow the same spec, how will we handle the diversity of designs, and how will this informs the design and testing of TVM?
I see us going two ways: (1) We try to adopt a single design entry language for all variants of VTA, e.g. Chisel. Since it’s the most hardware vendor agnostic and is friendly to ASIC development, it’s a safe bet moving forward but it means that we’ll end up having more complex code to maintain, and not necessarily achieve as high of performance as we might using High-Synthesis design languages designed by the vendors (Intel, Xilinx) that more seamlessly map down to the FPGA hardware. (2) We embrace the diversity of needs from TVM/VTA users and continue to maintain HLS, OpenCL, C, and Chisel sources. To keep this challenge tractable, and make sure that these sources are well tested and don’t bitrot, we need to make sure that each can follow a VTA spec via regular CI testing, which can test different variants of VTA (e.g. different sets of ALU instructions being supported, support for virtual threading or not, etc.)
I’d be curious to know what all of your thoughts are about (1) or (2), or a possible third option. This is no RFC, or vote, but I’d like to have your thoughts on this matter since it may affect how we prioritize open source work around VTA.
Finally some lower level comments for @zhanghaohit and @remotego:
Thanks everyone for the discussion, and thanks @thierry for bringing up the topic of language/framework choice for the VTA core. I wish to share some of my thoughts on this topic.
As a FPGA engineer, I mostly wrote VHDL/verilog codes for my past projects. I must admit that I am not very familiar with chisel. But as far as I know, Chisel is still a Hardware Description Language (like VHDL/verilog) designed to describe digital circuits. On the other hand, Xilinx HLS/Accel/Intel HLS/OpenCL are high level synthesis frameworks which converting algorithms written in software codes into hardware design.
The differences between HDL and SW languages are quite substantial. In my opinion, HDL languages are not programming languages, they are tools helping to describe low-level hardware circuits. We should always design the circuits first before we describing them in HDLs.
Code re-usability is always an interesting topic in the HDL world. As HDLs are usually dealing with low-level hardware libraries, it is very much dependent on the low-level hardware components/IPs available on the hardware devices. In practice, it is always much more difficult to re-use HDL codes than SW codes, especially when performance/efficiency is a concern. Regarding to FPGA devices, that is mainly because different devices have different kind of resources / IPs / interconnect interfaces, even different CLB structures.
On the other hand, high-level SW codes are focused to describe algorithms. It is mainly the compiler’s job to map/translate it efficiently into the hardware circuits. In theory, as I see it, they are better candidates to minimize the number of design sources as low level hardware details are hidden into the toolkits themselves. However, the current state of HLS is not very mature, and a lot of design ideas could not be realized via HLS, and many #pragmas have to be introduced to aid the compiler optimizations.
I like your comment on this topic, and I highly recommend trying Chisel for future HDL projects, as Chisel would actually help you define and connect interconnect interfaces with Bundle, without assuming compiler’s translation to be efficient.
Thank you for your reply! I will definitely try Chisel next time!
I agree with you that for HDLs like Chisel, we do not depend on compiler’s ability to make circuits efficient. In fact, as I mentioned in my previous post, in my opinion of course, HDLs are not a programming languages: we use HDLs to describe the circuit we designed. The efficiency of the circuit depend entirely on how we design the circuits.
Seems like we are converging.
Another aspect that @thierry mentioned, and I would like to extend a bit that we need to make sure that each design entry can follow a VTA spec via regular CI testing. For now the unit test and integration test script ensures the correctness of the existing three design entries, e.g. HLS based design entry is checked via FPGA based testing, C based design entry is checked via FSim, Chisel-based design entry is checked via TSIM. I think the proposed OpenCL-based design entry should fit into existing CI testing framework.
Hi
It seems that there is already runtime support for PCIe based FPGAs (TVM Monthly - July 2019). Is that right?
@liangfu @thierry @hjiang @remotego
@zhanghaohit
Thank you
Considering runtime support, I think the answer is yes, see https://github.com/apache/incubator-tvm/pull/3554 . However, to run the VTA tutorials on PCIe based FPGAs, driver-level support is not yet implemented.
Hi,
I think the runtime support here (https://github.com/apache/incubator-tvm/pull/3554) is for uop and instructions sync via PCIe. However, if we want to run a full network (e.g., Resnet), we’re still missing layer-wise synchronization/device_copy if two adjacent layers are resident in different devices.
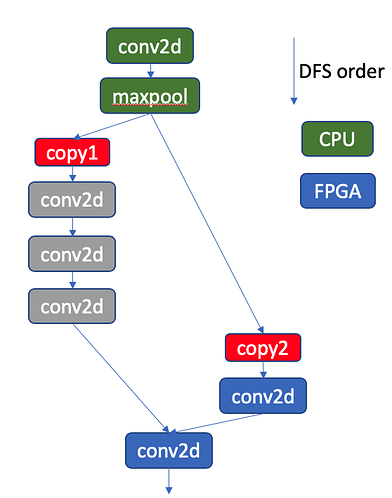
For example, in the above figure, we have to auto-insert a device_copy op between maxpool and conv2d.
Thank you for the reply @remotego, I agree with your views. As you mentioned, using OpenCL is a good way to bootstrap an accelerator design quickly. I myself did that with VTA when I wrote it in HLS as a grad student, so I see its value!
There are definitely strong pros/cons of HDLs vs. HLS languages. Ultimately if we want to give people choice, we should have a good CI testing story as Liangfu pointed out. But I do encourage you to give Chisel a try. It gives you the best of both worlds in terms of building higher abstractions (e.g. Bundle), while providing a good and easy to interpret mapping to RTL.
That said we welcome this addition in OpenCL. For now we’ll need to address the lack of consistent CI testing framework for the multitude of designs we have for VTA. @liangfu did you want to suggest some approaches there in an RFC? I’d be happy to work with you on that RFC.
Thank you @zhanghaohit.
In one of your posts above you mentioned that you have implemented theproposal. Have you tested it with some models? which fpga board you used? what are the performance numbers compared to vta on fpga soc? Is your code available in a repo somewhere? I really like to test it with some models and use it for my purpose. I don’t have enough time to add the driver support and inter layer synchronizations for my project.
Hi @elnaz92
Thanks for your interest. Yes, we’ve tested some models, e.g., Resnet_XX. Currently we’re using Intel A10. The performance on Cloud FPGA is much better than Edge FPGA (e.g., ultra96), as we have more resources to enlarge the GEMM core size. We’re still doing much performance optimization from both software and hardware aspects.
We’re preparing the code for PR, and the basic version should be ready soon.
Thanks @zhanghaohit
I like to have your opinion on using soft cores for pcie based fpgas. Rather than going through the high latency communications between the host and fpga or as you did running all the middle layers on the fpga itself, we can offload runtime stuff on a soft core (nios, microblaze, or better a riscv core). what’s the downsides here?
In my opinion, the performance of those soft cores are quite poor compare to server-grade processors (for processing speed, number of cores and memory bandwidth). I would estimate the overhead due to slow processor will be much larger than the overhead of PCIe communications.
Formal RFC is here: https://github.com/apache/incubator-tvm/issues/5840
PRs are here:
@elnaz92 You may checkout the code and try first.
Thanks for the PRs this is a very welcome contribution! Expect some initial comments/reviews tomorrow.
Hi,
We want to use TVM for our ADM-PCIE-KU3 (Xilinx Kintex UltraScale) FPGA board. I wanted to ask if TVM support for server-class FPGAs (PCIe connected) is stable? Does it provide the required driver support?