
Please do consider this. Also see What happened to x86 winograd?
The most important advantage of NCHWc is we split C into the inner and could vectorize it. I think if we do NHWC schedule we could achieve the same effect, which could make us reduce the convert layout and layout transform. This is why TFLite / TF choost NHWC layout The convert layout pass is not always good if we have shape transformation operator in models, like reshape / concat / squeeze and so on, this is very normal in object detection model.
For performance comparasion, please also consider the single thread. The TFLite’s thread pool is very very bad, the performance of single thread could reflect its power more.
For arm winograd, yes, we should port it into x86. Considered we have x86 NCHWc, we should do NCHWc winograd.
1 Like
For performance comparasion, please also consider the single thread. The TFLite’s thread pool is very very bad, the performance of single thread could reflect its power more.
Makes sense. I will add tomorrow. Have 2 devices at disposal, and they are doing tuning for now 
The convert layout pass is not always good if we have shape transformation operator in models, like reshape / concat / squeeze and so on, this is very normal in object detection model.
We can work on improving ConvertLayout. I think it handles concat already. Reshape and Squeeze are not supported AFAIK. This is a separate topic, but in general over time, ConvertLayout should support a large number of operators. It is beneficial in general, not just for this discuss post.
For NHWC schedule and Winograd NCHWc efforts, we can handle them in separate PRs. Those require considerable efforts.
Nice!
This will bring extra layout transform ops and overhead cost, so I bring this into this post. I suspect NHWC schedule could achieve the same performance of NCHWc. If so, we don’t need do extra layout transform.
NHWC schedule, @jackwish has committed convolution (lack of depthwise convolution I remember). So we should bring this easily. NCHWc winograd has been done by @ajtulloch before (Improved Direct + Winograd NCHWc CPU implementation, with ResNet-50 results) But maybe need some effort to enable it. We could do it in another prs like you said.
I created an Issue here to track all the ideas - https://github.com/apache/incubator-tvm/issues/5340
I like the overall directions we are going toward. i.e. make most of the schedule template as generic as possible and allow easy selection of combinations during strategy declaration. This would come very handy when adding support for other CPU types
1 Like
Thanks all. The PR is merged.
For this discuss post, there is one item remaining. Should we add a TFLite AutoTVM tutorial (or append the existing TFLite compilation tutorial - https://docs.tvm.ai/tutorials/frontend/from_tflite.html#sphx-glr-tutorials-frontend-from-tflite-py to make it use the changes made in above PR?
There are 2 action items
- Use ConvertLayout to go to NCHW, so that AlterOpLayout can convert to NCHWc.
- Add an autotvm util function on the lines of
autotvm.remove_template(tasks, template_name)that gives TVM user some control of config options.
@FrozenGene let us know what you think about this.
@anijain2305 @FrozenGene Do we have any comparison between conv2d_spatial_pack_nhwc VS conv2d_spatial_pack_nchw for arm? One potential issue for current conv2d_spatial_pack_nhwc and conv2d_spatial_pack_nchw schedule is that, to achieve prefetch and register tiling friendly, we need to pack/unpack data layout internally in topi compute, which causes quite a lot overheads. This means if we just keep NCHW or NHWC layout in relay level, we can’t avoid these overheads. That is why we proposed NCHWc layout for x86 and use graph tuner to reduce layout transformation.
I agree we need to further improve CoverLayout pass to support more operators. However, if we can already get performance improve using ConverLayout + NCHWc schedule, it’s still worthy to recommend, or at least mention this in the tutorial.
The schedules comparison looks great.
Could we get the tutorials or scripts to reproduce the results reported here?
I see the commited code, but its usage is a little difficult for users who wants to apply tvm’s newest features.
I prefer creating another one tutorial. from_tflite should be like other frontend tutorial, which is just to show how to import model into tvm and run.
I prefer adding one util function so that users could choose it by themselves unless we find this should be the base and won’t consider other options.
I have searched the data from my computer everywhere. However I only find one quantized data performance I could publish.
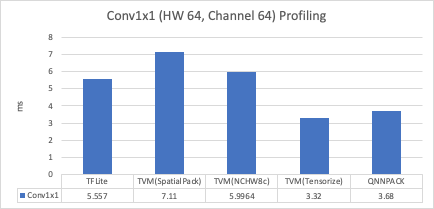
The spatial pack is NCHW layout (lack of NHWC). TVM tensorize is NHWC layout. I am sorry I lost the data of spatial pack of NHWC. Spatial pack of FP32 (NHWC) I remember it perform better than NCHW. NCHWc should not be collected.
I understand. Will try to get this in some kind of tutorial if possible. If that takes too much time, I will share a script to get you started.
Sorry, I did not understand this. Current tutorial - https://docs.tvm.ai/tutorials/frontend/from_tflite.html#sphx-glr-tutorials-frontend-from-tflite-py - shows how to import a TFLite model and compile and execute.
If I understand correctly, you are suggesting to write a new tutorial from scratch that shows how to run AutoTVM on TFlite models, right?
Yes. Your understanding is correctly. Current TFLite tutorial should just show how to import/compiler/execute like other frontend tutorial.
One possible way to organize the tutorial is that we add notes into “Compile tflite model” to guide user to read corresponding autotvm tutorial for optimization. One example is deploy ssd models tutorial. It contains a note section indicating where to go for optimization. For optimization, we can add a tflite model into “Auto-tuning a convolutional network for ARM CPU” tutorial, and show how to use ConvertLayout + NCHWc to get more performance. Does this sound reasonable?
Ok, I will spend some time writing a new tutorial - Autotuning a TFLite model for ARM.
I will run Auto-tvm with FP32 NHWC schedule. We can then compare ARM NCHW, ARM NHWC and Intel NCHWc, and decide if we want ConvertLayout in the tutorial.
In either case, in the tutorial we can discuss about all the possible options for the data layouts. And define what we can expect. I will try to keep all the options open - ARM NHWC, ARM NCHW and Intel NCHWc in the tutorial.
Thanks a lot!
I am very glad that you can share a script to help me start,
You can sent a message through the website MESSAGE.

I used NHWC schedule for tuning for mobilenet. Following is the result
| Network | TVM NCHWc (ms) | TFLite NHWC (ms) |
|---|---|---|
| mobilenet-v1 | 72.46 | 210.00 |
It seems current NHWC schedule requires deeper investigation. We lack a NHWC depthwise schedule. I also saw some warnings/errors while compiling/autotuning. Listing them here - these can tell the next steps. @FrozenGene can you take a look at improving NHWC schedule?
Compilation
- AlterOpLayout issue - https://github.com/apache/incubator-tvm/pull/5350 Might be possible to hide kernel layout change.
Auto-tuning
- Detect vectorize inside vectorized loop, ignoring…
- Large unroll factor -
result: MeasureResult(costs=(InstantiationError(['Too large factor for unrolling', 'Too large factor for unrolling'],),), error_no=1 - Timeout error -
result: MeasureResult(costs=(TimeoutError(),), error_no=6
I also created a quick tutorial here - https://github.com/apache/incubator-tvm/pull/5354
This is a tutorial on tuning a TFLite model for ARM CPUs. This tutorial is largely based on previous two tutorials.
- Compile TFLite Models - https://docs.tvm.ai/tutorials/frontend/from_tflite.html#sphx-glr-tutorials-frontend-from-tflite-py
- Auto-tuning a convolutional network for ARM CPUs - https://docs.tvm.ai/tutorials/autotvm/tune_relay_arm.html#sphx-glr-tutorials-autotvm-tune-relay-arm-py
Actually, it is mostly a copy paste of 2 tutorials. The interesting change is only this - https://github.com/apache/incubator-tvm/pull/5354/files#r409919577
I am not sure if we need a new tutorial that is 90% same to previous tutorials? @tqchen Do you have any comments?
@kindlehe you can use the script in the tutorial to get started.
sure.
This should be NHWC schedule problem.
It is normal. Because we have max_unroll to restrict it.
It it normal. When we have unroll, sometimes we will meet build time out. If the schedule is not good, we will meet runtime out error. I think it is accetable.
Maybe we could just add one TFLite network on Auto-tuning a convolutional network for ARM CPUs and add one section note in Compile TFLite Models to instruct users know how to get better performance leveraging AutoTVM.