– with @ajtulloch
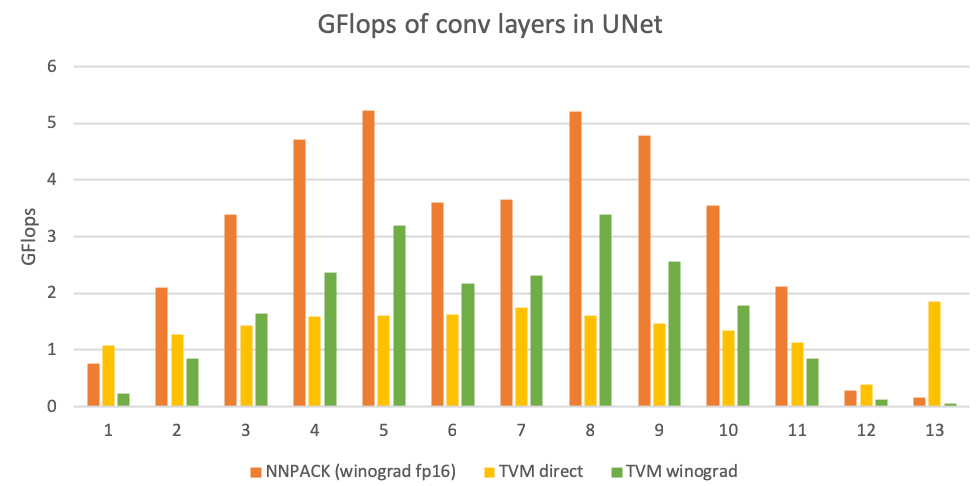
Lately, we’ve been testing the performance of a UNet model on armv7. The model makes extensive use of 3x3 convolutions, which makes it a suitable target for testing winograd performance. The F(6x6, 3x3) Winograd implementation in NNPACK is highly efficient on these convolutions, enabled by hand crafted assembly microkernels to work around deficiencies in Clang/LLVM code generation.
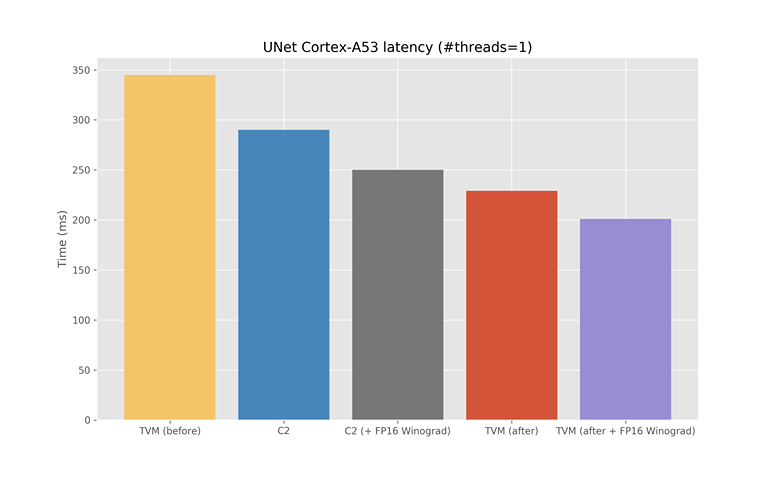
Despite our best effort, it’s still hard to beat the hand tuned assembly microkernels in NNPACK. Instead, we decided to take a hybrid approach – invoking NNPACK from TVM for the intermediate layers (where NNPACK performs well above arithmetic peak) and replace the less compute intensive layers (where NNPACK performs poorly) with TVM autotuned implementations. By integrating NNPACK with TVM (trivial with TVM’s ExternOp support, see PR #2084), and making it tunable with AutoTVM, TVM can choose the best implementation (and indeed, the best NNPACK-internal execution strategy). By replacing the first and last two convs (with relatively small channel counts and large spatial dimensions, performing at <0.5GFLOP/s) with direct convolutions (achieving >1GFLOP/s) and an autotuning schedule tuned on a cluster of fixed frequency Raspberry Pi 3B (4 x Cortex-A53 @ 0.6 GHz), we improve the model runtime substantially.
We’ve also improved the scheduling of TVM’s generated fused operators and reduced runtime by another ~10% or so. The main blocks we fuse are MaxPool/ReLU blocks and ResizeNearest/Add/ReLU blocks — which can incidentally be fused into our TVM convolutions for layers where we don’t select NNPACK.
Overall, we see 20% improvement compared to our current Caffe2/NNPACK baseline. We see similar improvements (in both Caffe2 and TVM) by using our FP16 Winograd variant. Compared to our pure TVM baseline, we improve by roughly 40%. All code is available in https://github.com/ajtulloch/tvm/commits/nnpack-precompute-ARM