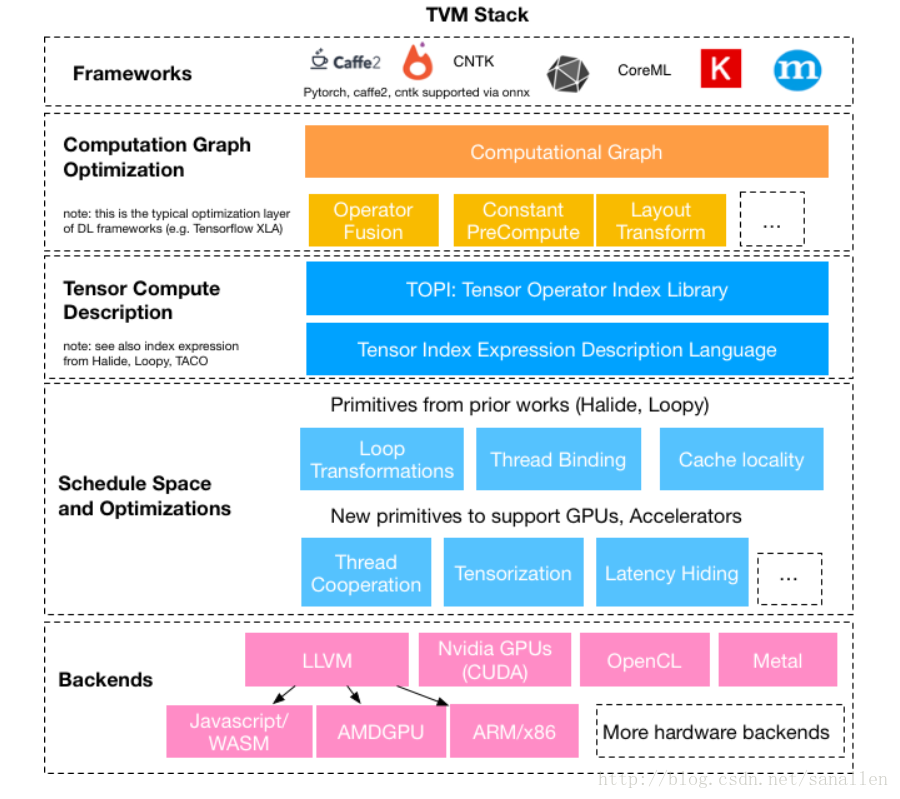
TVM contains different aspects/packages such as topi, nnvm, tvm, and vta. I would like to know what is the relation among them, i.e. which is more abstract than which. What I think it should be topi >> nnvm >> tvm >> vta, but I did not find any direct proof from the documents.
Also, is there a graph to show the lifetime of these different representations (maybe these are not presentations)? I mean LLVM have something like C/C++/… ==> AST ==> LLVM/IR ==> LLVM/MIR ==> ELF/… I think TVM should have something similar.
Can anyone who is familiar with TVM give me an answer? Thanks