
I am trying to optimize inference on multi-core cpu. It seems to me that the thread_pool.cc and threading_backend.cc files are for parallelism within one node(operator), eg. parallelism within one conv operation. I am wondering which files are regarding the node-level parallelism? For example, scheduling multiple different conv kernel operations to different cores/threads? Thanks!
TVM haven’t done this feature. It should let NNVM / Relay do data-flow analyze and find nodes haven’t data dependent, then we could make these nodes run on multi-core cpu. This feature could have performance improvement on models have branch and branched nodes are very small.
Thank you so much! If we want to implement this feature, where should I start? For example, how can I bind the different independent operations to different threads? I guess I should modify the build() function to do that, am I right? Thanks!
Hi FrozenGene,
In GoogLeNet, there are parallel branches as shown in following figure:
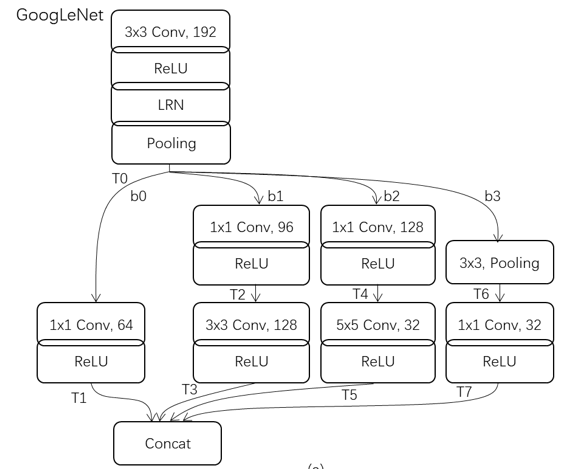
Possbile op execution sequences are:
T0->T1->T2->T3->T4->T5->T6->T7
T0->T1->T6->T7->T4->T5->T2->T3
How does Relay/TVM determine the op execution sequences now?
Thank you
TVM runtime currently topologically traverse the graph and execute each of the nodes in a sequential way.
The execution order of the “parallel” nodes are consistent to what they are stored in the json file.
2 Likes
Can we make node-level parallelism on gpu?Did you find way to run node-level parallelism on cpu?@ wolverines@ FrozenGene