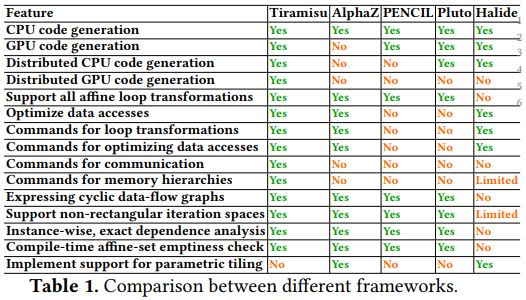
It is interesting. Please note that while TVM uses HalideIR that is derived from Halide, most of the code generation and optimization passes are done independently(with deep learning workloads in mind), while reusing sensible ones from Halide. So in terms of low level code generation, we are not necessarily bound to some of limitations listed.
In particular, we take a pragmatic approach, to focus on what is useful for deep learning workloads, so you can find unique things like more GPU optimization, accelerator support, recurrence(scan). If there are optimizations that Tiramisu have which is useful to get the state of art deep learning workloads, we are all for bringing that into TVM
I also want to emphasize that TVM is more than a low level tensor code generation, but instead trying to solve the end to end deep learning compilation problem, and many of the things goes beyond the tensor code generation.