
I found a very confusing result.
This image shows the result when I run arm_cpu_imagenet_bench.py. The latency of mobilenet was very fast: 38.01 ms

However, If I use TVM to run a real tensorflow mobilenet model, the result like:
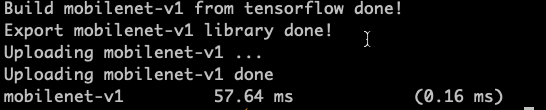
The same phenomenon also happened in resnet50 and vgg16. The difference is more than twice when I run my tensorflow model than run arm_cpu_imagenet_bench.py. I think auto-tuning may not work for both situations.
I am confusing about why the difference is so big. And I also found in vgg.py, the structure of vgg16 is not like a real tensorflow vgg16 model. The input channel and output channel of vgg16 generated by vgg.py are always the same(64 * 64, 128 * 128 …). But in my pre-trained vgg16, there are some filters like 64 * 128 and 128 * 256, just like that. The MACs of the generated model seems larger than a real model. But the latency is very small. Are there some problems here? Or is there a problem with my configuration?
Thanks very much for your patient. I am looking forward to your reply.
My environment:
TVM version: v0.5
Android NDK: r16b
Android Device: Xiaomi 6 with Snapdragon 835, and I used --model pixel2
Host Environment: Mac OS 10.14.3
Host compiler: LLVM
import os
from tvm.contrib.util import tempdir
import nnvm.testing
import nnvm.compiler
import tvm
from tvm.contrib import graph_runtime as runtime
import tflite.Model
from PIL import Image
from matplotlib import pyplot as plt
import numpy as np
from tvm import relay
from tvm.contrib import ndk
import argparse
# Tensorflow imports
import tensorflow as tf
import tvm.relay.testing.tf as tf_testing
NET_DIC = {
'mobilenet-v1' : 'mobilenet_v1_1.0_224.pb',
'mobilenet-v2' : 'mobilenet-v2-1.0.pb',
'inception-v3' : 'inception_v3.pb',
'inception-v4' : 'inception_v4.pb',
'resnet50-v2' : 'resnet-v2-50.pb',
'vgg16' : 'vgg16.pb'
}
def evaluate_network(target, target_host, repeat, network, image_size):
from PIL import Image
img_name = './elephant-299.jpg'
image = Image.open(img_name).resize((image_size, image_size))
x = np.array(image)
# connect to remote device
tracker = tvm.rpc.connect_tracker(args.host, args.port)
remote = tracker.request(args.rpc_key)
model_name = NET_DIC[network]
model_path = './'
with tf.gfile.FastGFile(os.path.join("./", model_name), 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
graph = tf.import_graph_def(graph_def, name='')
# Call the utility to import the graph definition into default graph.
graph_def = tf_testing.ProcessGraphDefParam(graph_def)
# Add shapes to the graph.
# with tf.Session() as sess:
# graph_def = tf_testing.AddShapesToGraphDef(sess, 'softmax')
print("Parse from tensorflow graph done!")
input_tensor = 'input'
input_shape = (1, image_size, image_size, 3)
# input_tensor = 'DecodeJpeg/contents'
# input_shape = x.shape
shape_dict = {input_tensor: input_shape}
func, params = relay.frontend.from_tensorflow(graph_def, layout='NCHW', shape=shape_dict)
print("Load %s from tensorflow done!" % network)
with relay.build_module.build_config(opt_level=3):
graph, lib, params = relay.build(func, target=target, params=params, target_host=target_host)
print("Build %s from tensorflow done!" % network)
tmp = tempdir()
if 'android' in str(target):
from tvm.contrib import ndk
filename = "%s.so" % network
lib.export_library(tmp.relpath(filename), ndk.create_shared)
else:
filename = "%s.tar" % network
lib.export_library(tmp.relpath(filename))
print("Export %s library done!" % network)
# upload library and params
print("Uploading %s ..." % network)
ctx = remote.context(str(target), 0)
remote.upload(tmp.relpath(filename))
print("Uploading %s done" % network)
rlib = remote.load_module(filename)
module = runtime.create(graph, rlib, ctx)
data_tvm = tvm.nd.array(x.astype('float32'))
module.set_input(input_tensor, data_tvm)
module.set_input(**params)
# evaluate
ftimer = module.module.time_evaluator("run", ctx, number=1, repeat=repeat)
prof_res = np.array(ftimer().results) * 1000 # multiply 1000 for converting to millisecond
print("%-20s %-19s (%s)" % (network, "%.2f ms" % np.mean(prof_res), "%.2f ms" % np.std(prof_res)))
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--model", type=str, default='pixel2',
help="The model of the test device. If your device is not listed in "
"the choices list, pick the most similar one as argument.")
parser.add_argument("--host", type=str, default='0.0.0.0')
parser.add_argument("--port", type=int, default=9190)
parser.add_argument("--rpc-key", type=str, default='android')
parser.add_argument("--repeat", type=int, default=100)
parser.add_argument("--network", type=str, default='mobilenet-v1')
parser.add_argument("--image_size", type=int, default=224)
args = parser.parse_args()
dtype = 'float32'
target = tvm.target.arm_cpu(model='pixel2')
target_host = None
print("--------------------------------------------------")
print("%-20s %-20s" % ("Network Name", "Mean Inference Time (std dev)"))
print("--------------------------------------------------")
evaluate_network(target, target_host, args.repeat, args.network, args.image_size)