
The goal of this RFC is to offload subgraph inference from user devices to high performance edge servers. The initial code is available here, which implements inference offloading based on BYOC.
Motivation
The benefit of offloading inference is like as follows:
- In the 5G era, the network latency is very low. We can make use of high-spec hardware in the cloud for better performance.
- In some cases, we don’t want to expose the whole network structure or weight data to users to protect intellectual property.
It is hard work to implement efficient inference offloading for each neural network by hand. We can do it automatically if TVM has a runtime support for offloading.
Use case
The figure illustrates Mask R-CNN inference on an iPhone device.
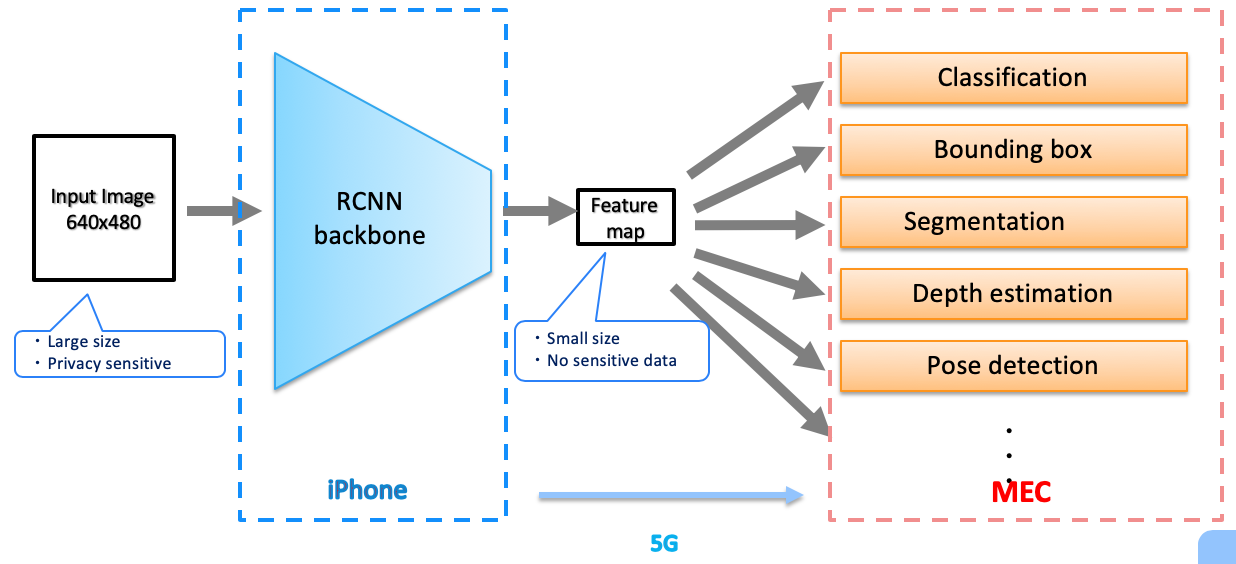
With the subgraph offloading feature, we can run the R-CNN backbone on the iPhone, send an encoded feature map to the MEC server, and run the head parts on the MEC server. Each stage can be parallelized in a pipeline fashion.
We shouldn’t send a raw input image to the server because the original picture is a privacy sensitive data and, in addition, its size is too big to be sent over the network. Instead, the encoded feature map can be smaller and less sensitive than the original input.
I’ve implemented a PoC application for this and confirmed that we can show more than 70 FPS. Such performance is unlikely to be achieved only on the iPhone device.
Here is a demo video: https://youtu.be/7MHIfdq2SKU
Proposal
Workflow
-
Build
-
Add annotation to specify which part of the graph should be offloaded to the remote edge server. [PoC code]
-
Unlike the other BYOC examples, we do nothing in relay.ext.remote. It is because,
- TVM doesn’t allow calling another relay.build inside relay.build.
- The content of subgraph should be updatable separately.
Instead, we build the subgraph part separately. [PoC code]
-
-
Deploy
- Place the separately built library on the remote server. [PoC code]
- Run inference server to process inference requests from edge devices.
Architecture
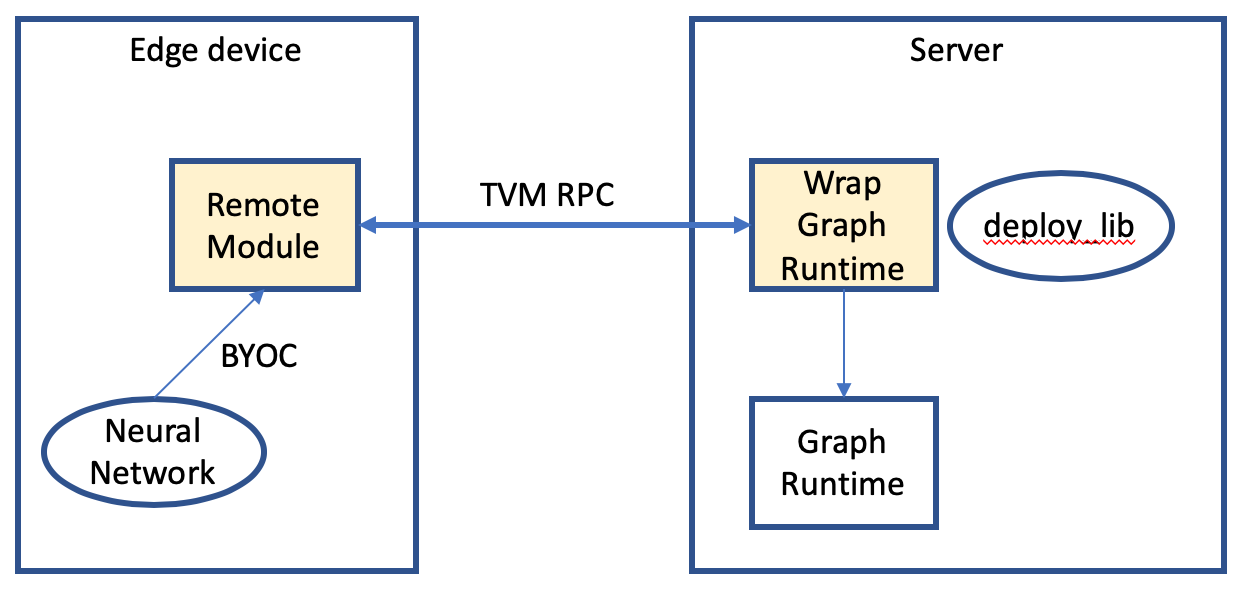
Two modules are introduced.
-
RemoteModule
This module is implemented based on BYOC. It calls the WrapGraphRuntime module via RPC. We cannot call the remote GrapRuntime directly because the subgraph structure and weight data are located on the remote server.
-
WrapGraphRuntime
This module calls the local GraphRuntime using the deployed library.
RPC protocol
Since we don’t have an official inference server for TVM, I think of starting from using the TVM RPC server to serve inference requests. There are some points which should be improved.
-
Bulk read/write
dmlc::Stream::{ReadArray,WriteArray} repeat read and write for the number of elements, which is not efficient.
-
Handle requests from multiple clients at the same time.
Not sure why we don’t allow concurrent RPC requests now. I support it on my PoC implementation with a quick patch temporarily.
-
Reduce the number of round-trips
This is probably beyond the scope of the TVM RPC, but it’d be more efficient if we can do the below with a single RPC.
- Send input tensors from local to remote
- Run the remote function
- Receive output tensors from remote to local
Supporting more standard protocols like GRPC, HTTP is future work. I think it’s also possible to cooperate with other inference servers like Tensorflow serving, TensroRT inference server, and so on.
Any comments would be appreciated.