Thank you, yes.
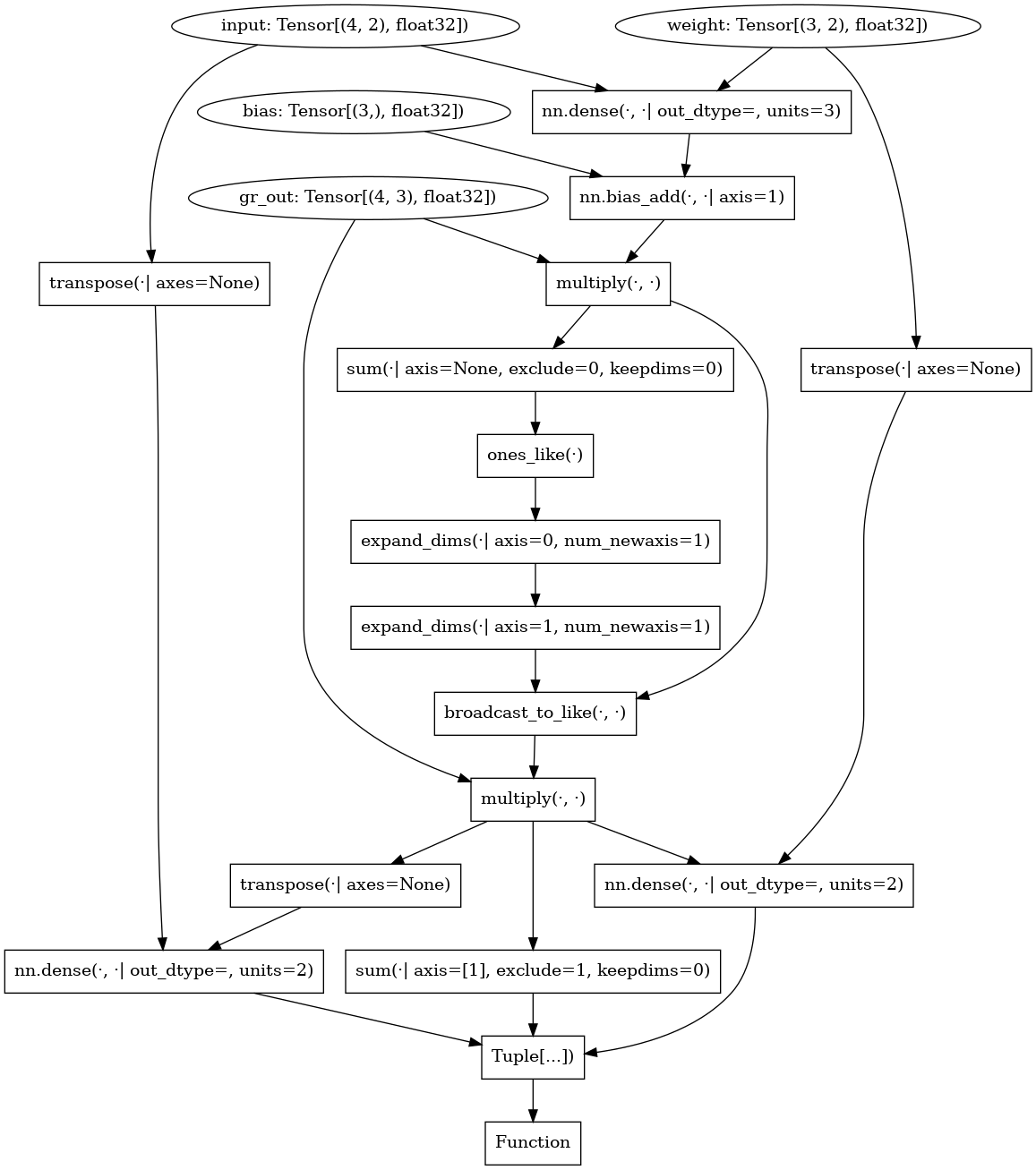
So I have this graph produced by gradient (and graph normal form and removing the forward outputs) of a dense + bias_add. Obviously, the gradients would be ones_like(output).collapse_like(bias) and a couple of dense( ) with grad_out or its transpose replacing weight and input, respectively for getting the gradient for the other.
The two passes I applied so far are
class ZeroZapp(tvm.relay.dataflow_pattern.DFPatternCallback):
def __init__(self):
self.pattern_tensor = tvm.relay.dataflow_pattern.wildcard()
self.zeros_like = tvm.relay.dataflow_pattern.is_op("zeros_like")(self.pattern_tensor)
self.other_tensor = tvm.relay.dataflow_pattern.wildcard()
self.pattern = self.zeros_like + self.other_tensor
def callback(self, pre, post, node_map):
rt = node_map[self.pattern][0]
ot = node_map[self.other_tensor][0]
if (ot._checked_type_ == rt._checked_type_):
return ot
else:
return tvm.relay.broadcast_to(ot, rt._checked_type_.shape)
class CollapseSumZapp(tvm.relay.dataflow_pattern.DFPatternCallback):
def __init__(self):
self.data_tensor = tvm.relay.dataflow_pattern.wildcard()
self.pattern_tensor = tvm.relay.dataflow_pattern.wildcard()
self.pattern = tvm.relay.dataflow_pattern.is_op("collapse_sum_like")(self.data_tensor, self.pattern_tensor)
def callback(self, pre, post, node_map):
data = node_map[self.data_tensor][0]
res = node_map[self.pattern][0]
if (data._checked_type_ == res._checked_type_):
return data
else:
return res
grfn = tvm.relay.dataflow_pattern.rewrite(ZeroZapp(), grmod["main"])
grfn = tvm.relay.dataflow_pattern.rewrite(CollapseSumZapp(), grfn)
For the CollapseSumZapp in particular, I would replace the if in the callback by a more refined pattern. Similarly,
So from implicit broadcasting, I have many ops in the backward. The broadcast_like could probably treated just as collapse_sum_like.
Similarly, I might have a reshape, broadcast_to, … that where I have a shape annotation for the input and output or I could take the input shape and the shape argument, but I don’t know how to use these.
The infinite loop probably was from me doing stupid things (re-creating the final step of the caculation instead of returning the original one…).
I’m always wondering whether I’m missing ready-made passes of removing some of the typical overhead of automatic differentiation (e.g. replacing ..._like with static ops or removing broadcasting / collapse_sum etc. If not, would these be useful to make available?
Best regards
Thomas


 (But
(But  Maybe if there were some way of saying I want types…
Maybe if there were some way of saying I want types…