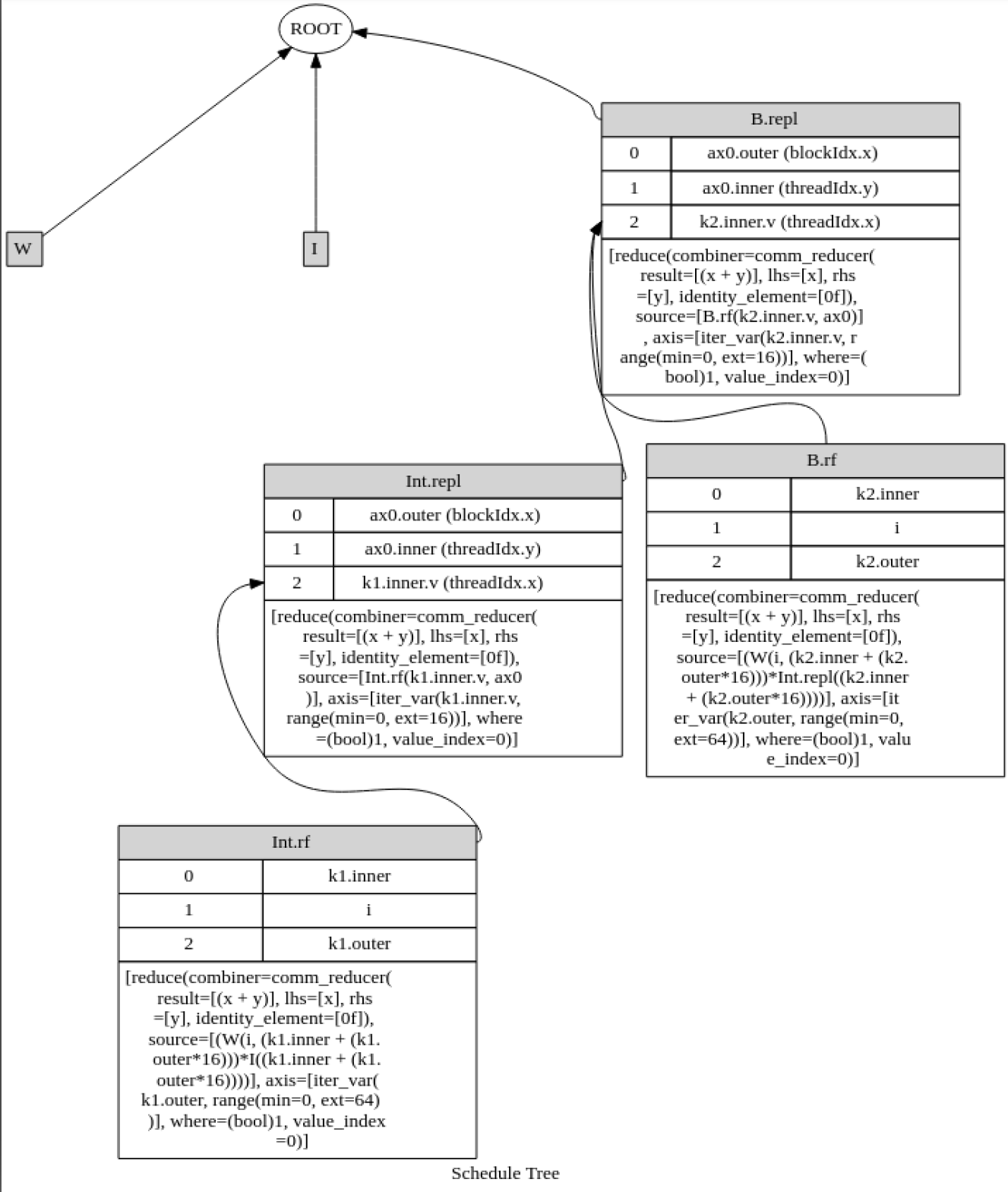
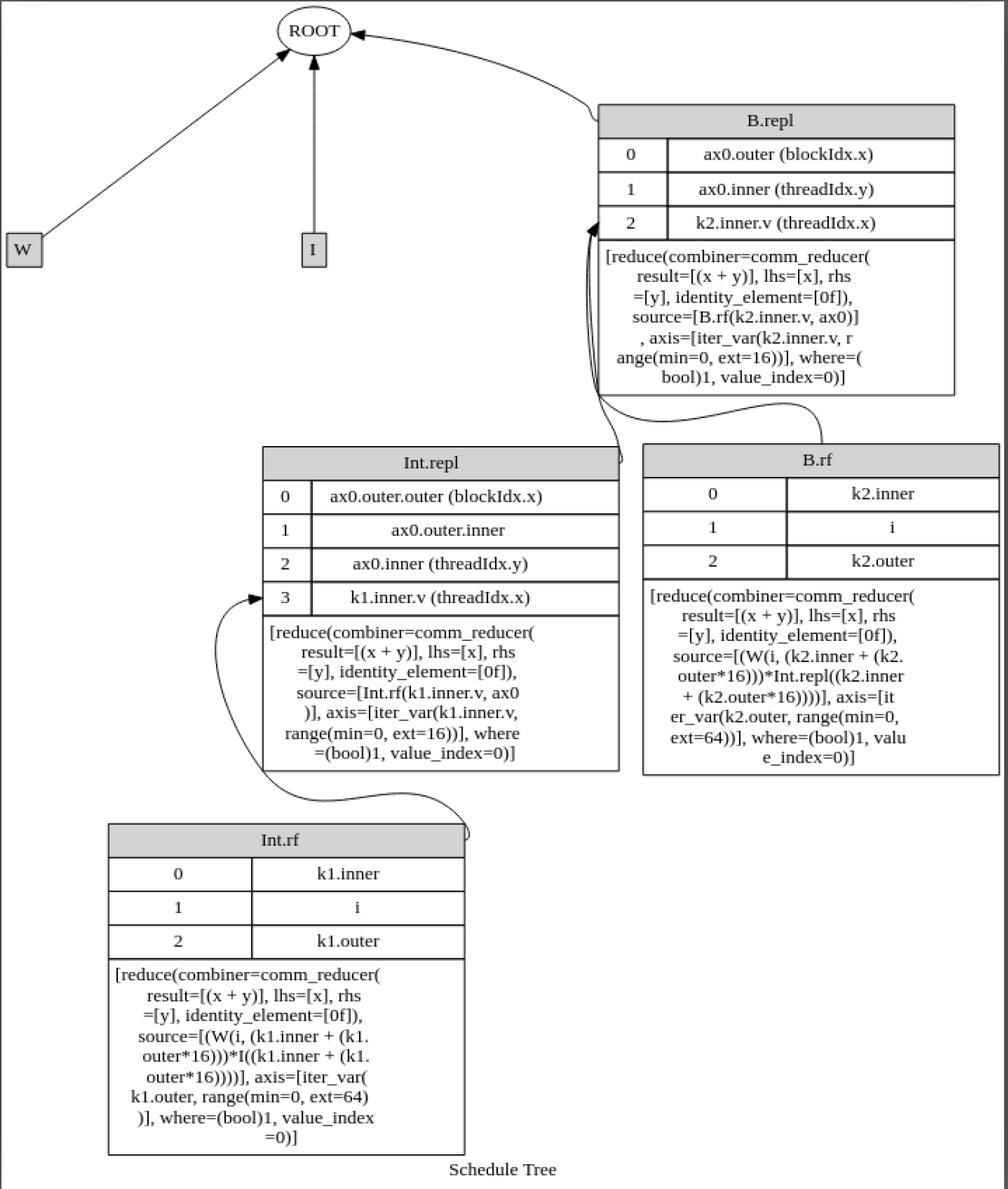
Consider the tvm computation and schedule below.
from __future__ import absolute_import, print_function
import tvm
import numpy as np
from utils import print_module_cuda
with tvm.build_config(detect_global_barrier = True):
# Input declarations
m = 1024
W = tvm.placeholder((m, m), name='W')
I = tvm.placeholder((m,), name='I')
# Matrix vector multiplication 1
k1 = tvm.reduce_axis((0, m), "k1")
Int = tvm.compute((m,), lambda i: tvm.sum(W[i, k1] * I[k1], axis=k1), name="Int")
# Matrix vector multiplication 2
k2 = tvm.reduce_axis((0, m), "k2")
B = tvm.compute((m,), lambda i: tvm.sum(W[i, k2] * Int[k2], axis=k2), name="B")
s = tvm.create_schedule(B.op)
bx = tvm.thread_axis("blockIdx.x")
ty = tvm.thread_axis("threadIdx.y")
tx = tvm.thread_axis("threadIdx.x")
# Schedule first multiplication
ko, ki = s[Int].split(Int.op.reduce_axis[0], factor=16)
IntF = s.rfactor(Int, ki)
xo, xi = s[Int].split(s[Int].op.axis[0], factor=32)
s[Int].bind(xo, bx)
s[Int].bind(xi, ty)
s[Int].bind(s[Int].op.reduce_axis[0], tx)
s[IntF].compute_at(s[Int], s[Int].op.reduce_axis[0])
s[Int].set_store_predicate(tx.var.equal(0))
# Schedule second multiplication
ko, ki = s[B].split(B.op.reduce_axis[0], factor=16)
BF = s.rfactor(B, ki)
xo, xi = s[B].split(s[B].op.axis[0], factor=32)
s[B].bind(xo, bx)
s[B].bind(xi, ty)
s[B].bind(s[B].op.reduce_axis[0], tx)
s[BF].compute_at(s[B], s[B].op.reduce_axis[0])
s[B].set_store_predicate(tx.var.equal(0))
s[Int].compute_at(s[B], s[B].op.reduce_axis[0])
print(tvm.lower(s, [W, I, Int, B], simple_mode = True))
fcuda = tvm.build(s, [W, I, Int, B], "cuda")
print(fcuda.imported_modules[0].get_source())
This runs to generate the following IR
produce B {
// attr [iter_var(blockIdx.x, , blockIdx.x)] thread_extent = 32
// attr [Int.rf] storage_scope = "local"
allocate Int.rf[float32 * 1]
// attr [reduce_temp0] storage_scope = "local"
allocate reduce_temp0[float32 * 1]
// attr [B.rf] storage_scope = "local"
allocate B.rf[float32 * 1]
// attr [reduce_temp0] storage_scope = "local"
allocate reduce_temp0[float32 * 1]
// attr [iter_var(threadIdx.y, , threadIdx.y)] thread_extent = 32
// attr [iter_var(threadIdx.x, , threadIdx.x)] thread_extent = 16
produce Int {
produce Int.rf {
Int.rf[0] = 0f
for (k1.outer, 0, 64) {
if (likely(((((blockIdx.x*32) + threadIdx.y) + threadIdx.x) < 1024))) {
Int.rf[0] = (Int.rf[0] + (W[((((blockIdx.x*32768) + (threadIdx.x*1025)) + (threadIdx.y*1024)) + (k1.outer*16))]*I[((k1.outer*16) + threadIdx.x)]))
}
}
}
// attr [comm_reducer(result=[(x + y)], lhs=[x], rhs=[y], identity_element=[0f])] reduce_scope = reinterpret((uint64)0)
tvm_thread_allreduce((uint32)1, Int.rf[0], ((((blockIdx.x*32) + threadIdx.y) < 1009) && ((((blockIdx.x*32) + threadIdx.y) + threadIdx.x) < 1024)), reduce_temp0, threadIdx.x)
if ((((blockIdx.x*32) + threadIdx.y) < 1009)) {
if ((threadIdx.x == 0)) {
Int[(((blockIdx.x*32) + threadIdx.y) + threadIdx.x)] = reduce_temp0[0]
}
}
}
produce B.rf {
B.rf[0] = 0f
for (k2.outer, 0, 64) {
B.rf[0] = (B.rf[0] + (W[((((blockIdx.x*32768) + (threadIdx.y*1024)) + (k2.outer*16)) + threadIdx.x)]*Int[((k2.outer*16) + threadIdx.x)]))
}
}
// attr [comm_reducer(result=[(x + y)], lhs=[x], rhs=[y], identity_element=[0f])] reduce_scope = reinterpret((uint64)0)
tvm_thread_allreduce((uint32)1, B.rf[0], (bool)1, reduce_temp0, threadIdx.x)
if ((threadIdx.x == 0)) {
B[((blockIdx.x*32) + threadIdx.y)] = reduce_temp0[0]
}
}
I have been reading the operational model of TVM scheduling primitives that some contributors are working on here. In the constraints for bind, it is said that multiple IterVars may not be bound to the same GPU thread Var if the IterVars are a part of the same loop nest. This certainly seems to be the case in the above example. Int is computed at the reduce axis of B and the loop nests of both B and Int have IterVars bound to the same GPU thread. The axis xo for example is bound to blockIdx.x in both cases, and due to the compute_at relation, they are a part of the same loop nest. What am I missing here?