I’m auto-tuing Resnet50 on Tesla V100 GPU. It’s always like this:
[Task 1/23] Current/Best: 0.00/ 0.00 GFLOPS | Progress: (160/2000) | 209.03 s
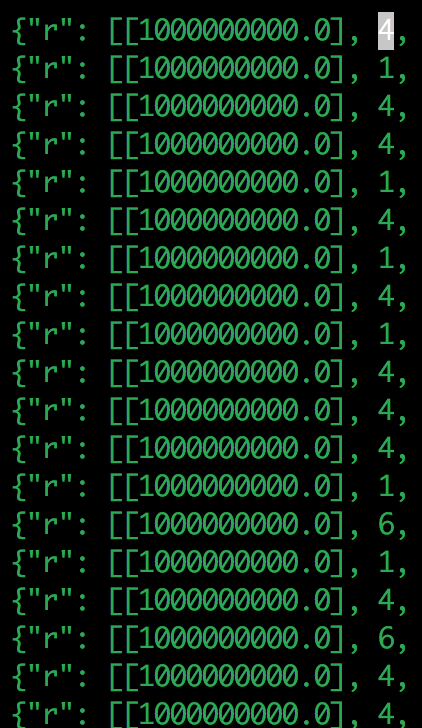
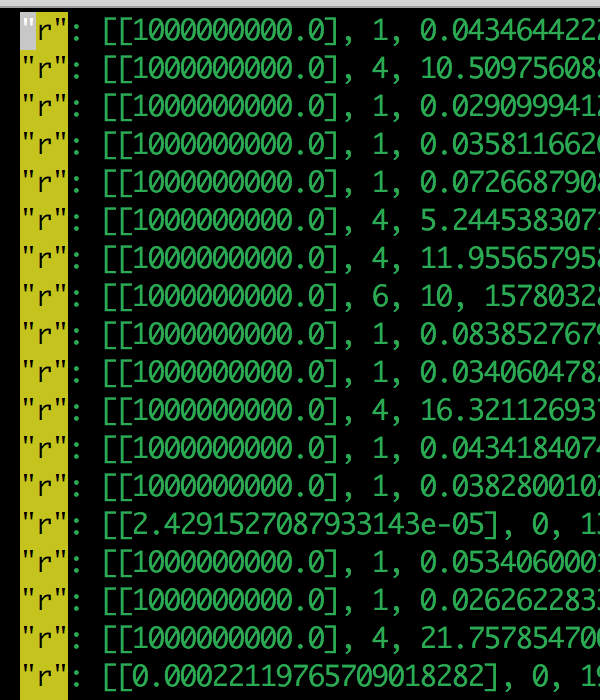
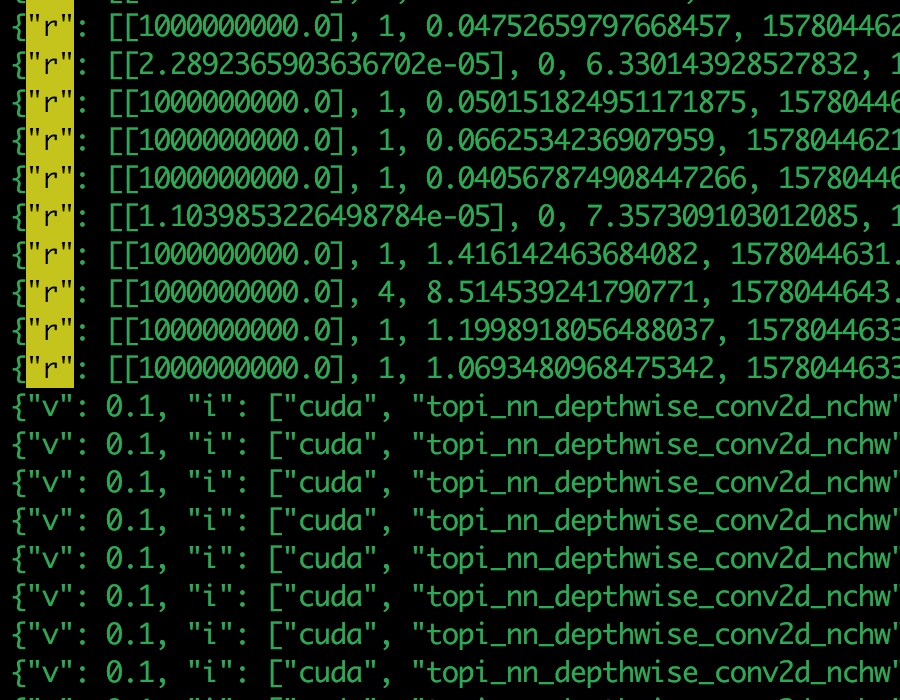
I opened the tmp log and copy one line. Seems it’s tuning conv2d and the input is 1X1024X14X14, and kernel shape is 2048X1024X1X1. This workload is not a heavy one, why it’s always 0.0 GFLOPS?
{“i”: [“cuda”, “topi_nn_conv2d”, [[“TENSOR”, [1, 1024, 14, 14], “float32”], [“TENSOR”, [2048, 1024, 1, 1], “float32”], [2, 2], [0, 0], [1, 1], “NCHW”, “float32”], {}, [“conv2d”, [1, 1024, 14, 14, “float32”], [2048, 1024, 1, 1, “float32”], [2, 2], [0, 0], [1, 1], “NCHW”, “float32”], {“i”: 111087, “t”: “direct”, “c”: null, “e”: [[“tile_f”, “sp”, [-1, 16, 128, 1]], [“tile_y”, “sp”, [-1, 7, 1, 1]], [“tile_x”, “sp”, [-1, 1, 1, 1]], [“tile_rc”, “sp”, [-1, 256]], [“tile_ry”, “sp”, [-1, 1]], [“tile_rx”, “sp”, [-1, 1]], [“auto_unroll_max_step”, “ot”, 512], [“unroll_explicit”, “ot”, 0]]}], “r”: [[1000000000.0], 1, 0.05721116065979004, 1578299411.1211495], “v”: 0.1}
 btw, could you change the title by adding [SOLVED] in the beginning to indicate this issue has been resolved? Thanks.
btw, could you change the title by adding [SOLVED] in the beginning to indicate this issue has been resolved? Thanks.