
I follow the tutorial on tune_relay_x86. When i auto-tune mobilefacenet, I encountered the following error
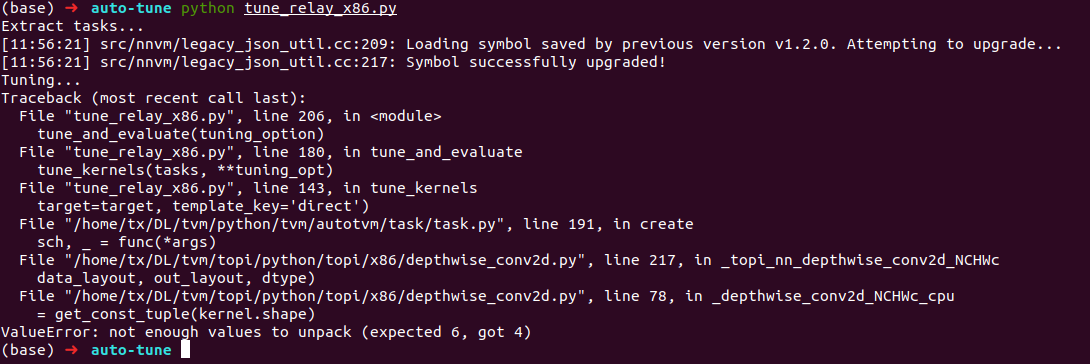
1 Like
This is an known issue. You need to make this change https://github.com/dmlc/tvm/pull/2184/files#diff-7e201f96ab2ff5c019d70eeabde2dc87R210. Will fix it in that PR

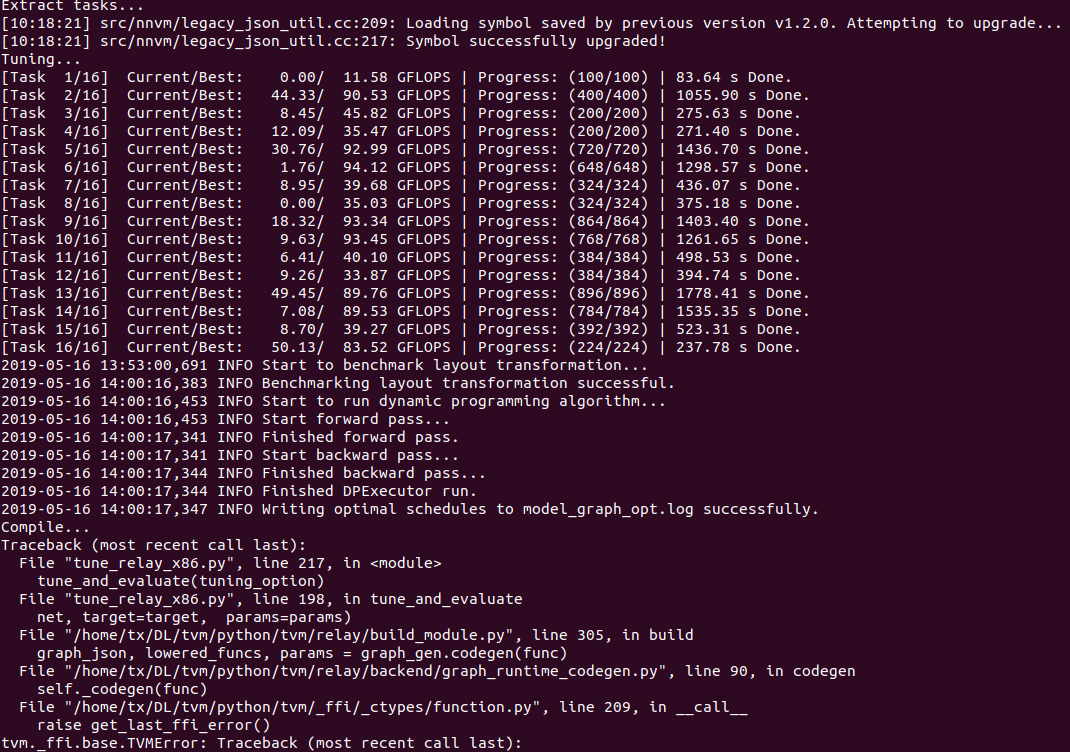
Looks like dense is loading a schedule, instead of using default schedule. Is the number of schedules in model_graph_opt.log the same as the number of conv2d in the model?
the conv2d number is not same, a full-connect layer is missing. after the full-connect layer is the batchnorm layer.
I have try auto-tune the resnet18_v1, the compile is ok except a warning of dense layer fallback.
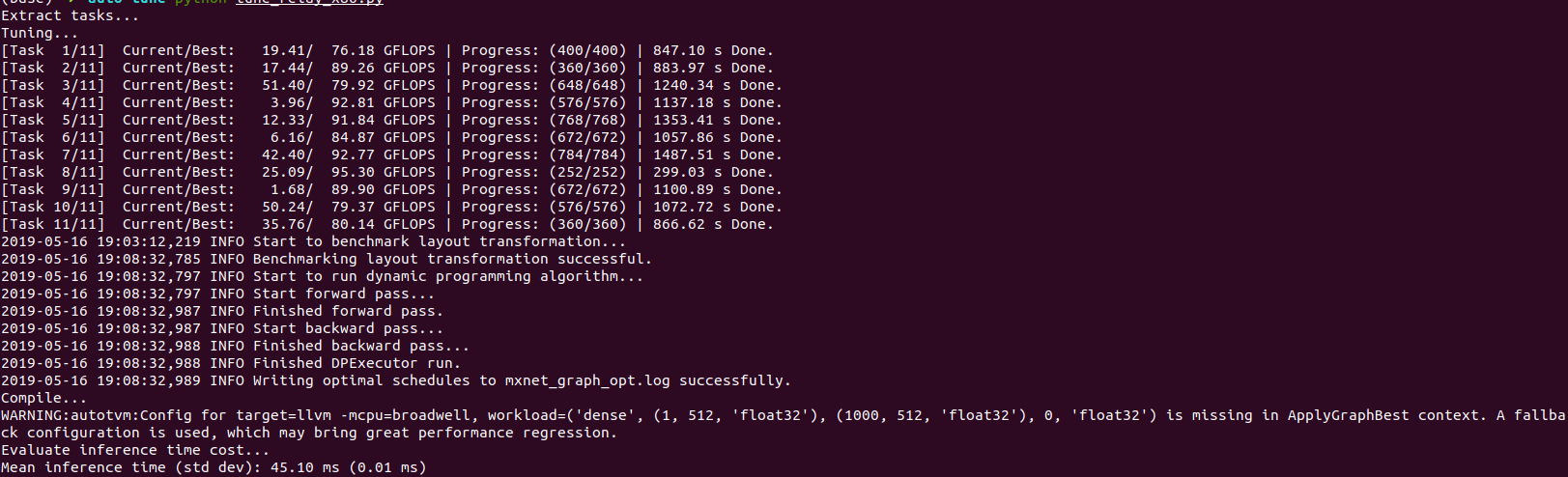
may be it is the problem of batchnorm layer?
I remove the full-connect layer and the following batchnorm layer, compile the network using the auto-tuned model_graph_opt.log.
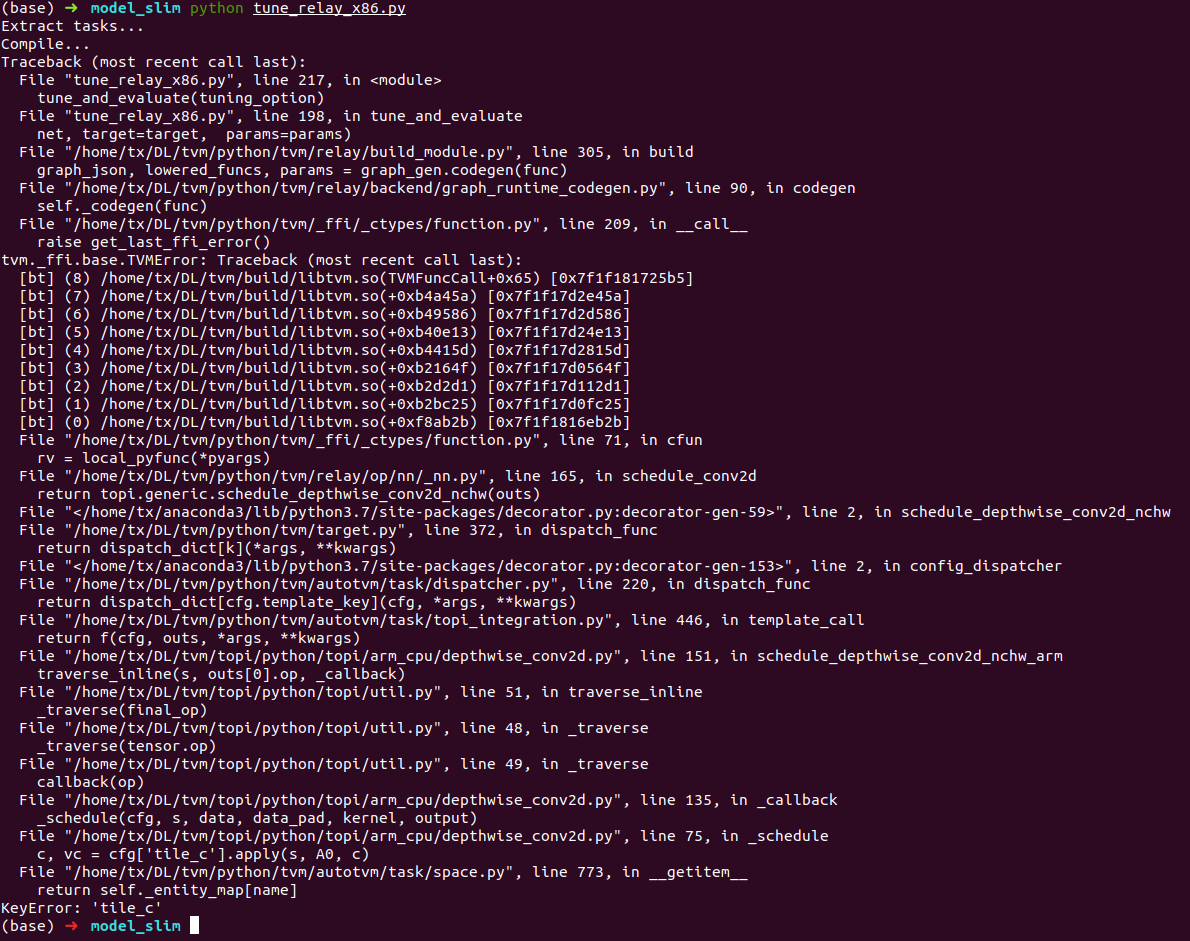
It called arm_cpu schedules. Is the target set correctly?
I set target = “llvm -mcpu=broadwell” and ctx = tvm.cpu() according to the tune_relay_x86.py example.
import os
import numpy as np
import tvm
from tvm import autotvm
from tvm import relay
from tvm.relay import testing
from tvm.autotvm.tuner import XGBTuner, GATuner, RandomTuner, GridSearchTuner
from tvm.autotvm.graph_tuner import DPTuner, PBQPTuner
import tvm.contrib.graph_runtime as runtime
import mxnet as mx
def get_network(name, batch_size):
“”“Get the symbol definition and random weight of a network”""
input_shape = (batch_size, 3, 224, 224)
output_shape = (batch_size, 1024)
if "resnet" in name:
n_layer = int(name.split('-')[1])
net, params = relay.testing.resnet.get_workload(num_layers=n_layer, batch_size=batch_size, dtype=dtype)
elif "vgg" in name:
n_layer = int(name.split('-')[1])
net, params = relay.testing.vgg.get_workload(num_layers=n_layer, batch_size=batch_size, dtype=dtype)
elif name == 'mobilenet':
net, params = relay.testing.mobilenet.get_workload(batch_size=batch_size, dtype=dtype)
elif name == 'squeezenet_v1.1':
net, params = relay.testing.squeezenet.get_workload(batch_size=batch_size, version='1.1', dtype=dtype)
elif name == 'inception_v3':
input_shape = (1, 3, 299, 299)
net, params = relay.testing.inception_v3.get_workload(batch_size=batch_size, dtype=dtype)
elif name == 'mxnet':
# an example for mxnet model
from mxnet.gluon.model_zoo.vision import get_model
block = get_model('resnet18_v1', pretrained=True)
net, params = relay.frontend.from_mxnet(block, shape={'data': input_shape}, dtype=dtype)
net = relay.Function(net.params, relay.nn.softmax(net.body), None, net.type_params, net.attrs)
elif name == 'model':
shape_dict = {'data':input_shape}
mx_sym, args, auxs = mx.model.load_checkpoint('model',115)
net, params = relay.frontend.from_mxnet(mx_sym, shape_dict, args, auxs)
else:
raise ValueError("Unsupported network: " + name)
return net, params, input_shape, output_shape
target = “llvm -mcpu=broadwell”
batch_size = 1
dtype = “float32”
model_name = “mxnet”
log_file = “%s.log” % model_name
graph_opt_sch_file = “%s_graph_opt.log” % model_name
num_threads = 1
os.environ[“TVM_NUM_THREADS”] = str(num_threads)
tuning_option = {
‘log_filename’: log_file,
‘tuner’: ‘random’,
‘early_stopping’: None,
'measure_option': autotvm.measure_option(
builder=autotvm.LocalBuilder(),
runner=autotvm.LocalRunner(number=10, repeat=1,
min_repeat_ms=1000),
),
}
def tune_kernels(tasks,
measure_option,
tuner=‘gridsearch’,
early_stopping=None,
log_filename=‘tuning.log’):
for i, tsk in enumerate(tasks):
prefix = "[Task %2d/%2d] " % (i+1, len(tasks))
op_name = tsk.workload[0]
if op_name == 'conv2d':
func_create = 'topi_x86_conv2d_NCHWc'
elif op_name == 'depthwise_conv2d_nchw':
func_create = 'topi_x86_depthwise_conv2d_NCHWc_from_nchw'
else:
raise ValueError("Tuning {} is not supported on x86".format(op_name))
task = autotvm.task.create(func_create, args=tsk.args,
target=target, template_key='direct')
task.workload = tsk.workload
if tuner == 'xgb' or tuner == 'xgb-rank':
tuner_obj = XGBTuner(task, loss_type='rank')
elif tuner == 'ga':
tuner_obj = GATuner(task, pop_size=50)
elif tuner == 'random':
tuner_obj = RandomTuner(task)
elif tuner == 'gridsearch':
tuner_obj = GridSearchTuner(task)
else:
raise ValueError("Invalid tuner: " + tuner)
n_trial=len(task.config_space)
tuner_obj.tune(n_trial=n_trial,
early_stopping=early_stopping,
measure_option=measure_option,
callbacks=[
autotvm.callback.progress_bar(n_trial, prefix=prefix),
autotvm.callback.log_to_file(log_filename)])
def tune_graph(graph, dshape, records, opt_sch_file, use_DP=True):
target_op = [relay.nn.conv2d]
Tuner = DPTuner if use_DP else PBQPTuner
executor = Tuner(graph, {“data”: dshape}, records, target_op, target)
executor.benchmark_layout_transform(min_exec_num=2000)
executor.run()
executor.write_opt_sch2record_file(opt_sch_file)
def tune_and_evaluate(tuning_opt):
# extract workloads from relay program
print(“Extract tasks…”)
net, params, data_shape, out_shape = get_network(model_name, batch_size)
tasks = autotvm.task.extract_from_program(net, target=target,
params=params, ops=(relay.op.nn.conv2d,))
# run tuning tasks
print("Tuning...")
tune_kernels(tasks, **tuning_opt)
tune_graph(net, data_shape, log_file, graph_opt_sch_file)
# compile kernels with graph-level best records
with autotvm.apply_graph_best(graph_opt_sch_file):
print("Compile...")
with relay.build_config(opt_level=3):
graph, lib, params = relay.build_module.build(
net, target=target, params=params)
# upload parameters to device
ctx = tvm.cpu()
data_tvm = tvm.nd.array((np.random.uniform(size=data_shape)).astype(dtype))
module = runtime.create(graph, lib, ctx)
module.set_input('data', data_tvm)
module.set_input(**params)
# evaluate
print("Evaluate inference time cost...")
ftimer = module.module.time_evaluator("run", ctx, number=100, repeat=3)
prof_res = np.array(ftimer().results) * 1000 # convert to millisecond
print("Mean inference time (std dev): %.2f ms (%.2f ms)" %
(np.mean(prof_res), np.std(prof_res)))
tune_and_evaluate(tuning_option)
here is the mxnet model file
link: https://pan.baidu.com/s/14O76Xex6eX1pYPvzwxMYGg code: 4kgw
input_shape = (batch_size, 3, 112, 112)
output_shape = (batch_size, 512)
could you try to auto-tune this model for help? thank you so much!
Looks like t setting target = “llvm -mcpu=broadwell” will make tvm use arm_cpu schedule. Can you verify this with a smaller network? If it is the case, this issue is not related to autotvm.
I have try on other computers, llvm -mcpu=haswell, and use the origin mobilefacenent(a smaller network 3.92M), the error is same. if I don’t do auto-tune, I can compile it using relay and nnvm. nnvm is faster. I can also use nnvm to auto-tune, the compile is ok. The “tile_k” key not found error occurs only if I auto-tune using relay. so I think it is the problem of autotvm with relay.
This sounds weird to me. Can you take a look at the log file after autotune and make sure x86 target is used?
model_graph_opt.log is like this:
{“i”: [“llvm -mcpu=broadwell”, “topi_x86_conv2d_NCHWc”, [[“TENSOR”, [1, 3, 112, 112], “float32”], [“TENSOR”, [64, 3, 3, 3], “float32”], [2, 2], [1, 1], [1, 1], “NCHW”, “float32”], {}, [“conv2d”, [1, 3, 112, 112, “float32”], [64, 3, 3, 3, “float32”], [2, 2], [1, 1], [1, 1], “NCHW”, “float32”], {“i”: 24, “t”: “direct”, “c”: null, “e”: [[“tile_ic”, “sp”, [3, 1]], [“tile_oc”, “sp”, [2, 32]], [“tile_ow”, “sp”, [28, 2]], [“unroll_kw”, “ot”, true]]}], “r”: [[0.00022216637243020992], 0, 2.0850822925567627, 1557991675.785746], “v”: 0.1}
{“i”: [“llvm -mcpu=broadwell”, “topi_x86_conv2d_NCHWc”, [[“TENSOR”, [1, 64, 56, 56], “float32”], [“TENSOR”, [64, 64, 1, 1], “float32”], [1, 1], [0, 0], [1, 1], “NCHW”, “float32”], {}, [“conv2d”, [1, 64, 56, 56, “float32”], [64, 64, 1, 1, “float32”], [1, 1], [0, 0], [1, 1], “NCHW”, “float32”], {“i”: 432, “t”: “direct”, “c”: null, “e”: [[“tile_ic”, “sp”, [2, 32]], [“tile_oc”, “sp”, [2, 32]], [“tile_ow”, “sp”, [56, 1]], [“tile_oh”, “ot”, 2]]}], “r”: [[0.00047231593158072126], 0, 3.1119916439056396, 1557989850.5378458], “v”: 0.1}
{“i”: [“llvm -mcpu=broadwell”, “topi_x86_depthwise_conv2d_NCHWc_from_nchw”, [[“TENSOR”, [1, 64, 56, 56], “float32”], [“TENSOR”, [64, 1, 3, 3], “float32”], [1, 1], [1, 1], [1, 1], “float32”], {}, [“depthwise_conv2d_nchw”, [1, 64, 56, 56, “float32”], [64, 1, 3, 3, “float32”], [1, 1], [1, 1], [1, 1], “float32”], {“i”: 89, “t”: “direct”, “c”: null, “e”: [[“tile_ic”, “sp”, [2, 32]], [“tile_oc”, “sp”, [2, 32]], [“tile_ow”, “sp”, [28, 2]]]}], “r”: [[0.00027373629171905875], 0, 3.663689613342285, 1557991313.0582528], “v”: 0.1}
{“i”: [“llvm -mcpu=broadwell”, “topi_x86_conv2d_NCHWc”, [[“TENSOR”, [1, 64, 56, 56], “float32”], [“TENSOR”, [64, 64, 1, 1], “float32”], [1, 1], [0, 0], [1, 1], “NCHW”, “float32”], {}, [“conv2d”, [1, 64, 56, 56, “float32”], [64, 64, 1, 1, “float32”], [1, 1], [0, 0], [1, 1], “NCHW”, “float32”], {“i”: 432, “t”: “direct”, “c”: null, “e”: [[“tile_ic”, “sp”, [2, 32]], [“tile_oc”, “sp”, [2, 32]], [“tile_ow”, “sp”, [56, 1]], [“tile_oh”, “ot”, 2]]}], “r”: [[0.00047231593158072126], 0, 3.1119916439056396, 1557989850.5378458], “v”: 0.1}
“tile_k” is not in this log.
Can you try to use autotvm.apply_history_best(log_file) as dispatch context and see what happens?
if i use apply_history_best, the error is “tile_c” key error. it well use arm cpu for depthwise conv.
WARNING:autotvm:Cannot find config for target=llvm -mcpu=haswell, workload=(‘dense’, (1, 512, ‘float32’), (128, 512, ‘float32’), 0, ‘float32’). A fallback configuration is used, which may bring great performance regression.
Traceback (most recent call last):
File “tune_relay_x86_mobilefacenet.py”, line 217, in
tune_and_evaluate(tuning_option)
File “tune_relay_x86_mobilefacenet.py”, line 198, in tune_and_evaluate
net, target=target, params=params)
File “/home/tx/DL/tvm/python/tvm/relay/build_module.py”, line 305, in build
graph_json, lowered_funcs, params = graph_gen.codegen(func)
File “/home/tx/DL/tvm/python/tvm/relay/backend/graph_runtime_codegen.py”, line 90, in codegen
self._codegen(func)
File “/home/tx/DL/tvm/python/tvm/_ffi/_ctypes/function.py”, line 209, in call
raise get_last_ffi_error()
tvm._ffi.base.TVMError: Traceback (most recent call last):
[bt] (8) /home/tx/DL/tvm/build/libtvm.so(+0xb44500) [0x7f21ad284500]
[bt] (7) /home/tx/DL/tvm/build/libtvm.so(+0xb40e13) [0x7f21ad280e13]
[bt] (6) /home/tx/DL/tvm/build/libtvm.so(+0xb44500) [0x7f21ad284500]
[bt] (5) /home/tx/DL/tvm/build/libtvm.so(+0xb40e13) [0x7f21ad280e13]
[bt] (4) /home/tx/DL/tvm/build/libtvm.so(+0xb4415d) [0x7f21ad28415d]
[bt] (3) /home/tx/DL/tvm/build/libtvm.so(+0xb2164f) [0x7f21ad26164f]
[bt] (2) /home/tx/DL/tvm/build/libtvm.so(+0xb2d2d1) [0x7f21ad26d2d1]
[bt] (1) /home/tx/DL/tvm/build/libtvm.so(+0xb2bc25) [0x7f21ad26bc25]
[bt] (0) /home/tx/DL/tvm/build/libtvm.so(+0xf8ab2b) [0x7f21ad6cab2b]
File “/home/tx/DL/tvm/python/tvm/_ffi/_ctypes/function.py”, line 71, in cfun
rv = local_pyfunc(*pyargs)
File “/home/tx/DL/tvm/python/tvm/relay/op/nn/_nn.py”, line 165, in schedule_conv2d
return topi.generic.schedule_depthwise_conv2d_nchw(outs)
File “</home/tx/anaconda3/lib/python3.7/site-packages/decorator.py:decorator-gen-59>”, line 2, in schedule_depthwise_conv2d_nchw
File “/home/tx/DL/tvm/python/tvm/target.py”, line 372, in dispatch_func
return dispatch_dict[k](*args, **kwargs)
File “</home/tx/anaconda3/lib/python3.7/site-packages/decorator.py:decorator-gen-153>”, line 2, in config_dispatcher
File “/home/tx/DL/tvm/python/tvm/autotvm/task/dispatcher.py”, line 220, in dispatch_func
return dispatch_dict[cfg.template_key](cfg, *args, **kwargs)
File “/home/tx/DL/tvm/python/tvm/autotvm/task/topi_integration.py”, line 446, in template_call
return f(cfg, outs, *args, **kwargs)
File “/home/tx/DL/tvm/topi/python/topi/arm_cpu/depthwise_conv2d.py”, line 151, in schedule_depthwise_conv2d_nchw_arm
traverse_inline(s, outs[0].op, _callback)
File “/home/tx/DL/tvm/topi/python/topi/util.py”, line 51, in traverse_inline
_traverse(final_op)
File “/home/tx/DL/tvm/topi/python/topi/util.py”, line 48, in _traverse
_traverse(tensor.op)
File “/home/tx/DL/tvm/topi/python/topi/util.py”, line 49, in _traverse
callback(op)
File “/home/tx/DL/tvm/topi/python/topi/arm_cpu/depthwise_conv2d.py”, line 135, in _callback
_schedule(cfg, s, data, data_pad, kernel, output)
File “/home/tx/DL/tvm/topi/python/topi/arm_cpu/depthwise_conv2d.py”, line 75, in _schedule
c, vc = cfg[‘tile_c’].apply(s, A0, c)
File “/home/tx/DL/tvm/python/tvm/autotvm/task/space.py”, line 773, in getitem
return self._entity_map[name]
KeyError: ‘tile_c’
https://github.com/dmlc/tvm/blob/master/topi/python/topi/arm_cpu/depthwise_conv2d.py#L29 Can you try to remove “cpu” target in this file, and just leave arm_cpu?
Extract tasks…
[17:26:37] src/nnvm/legacy_json_util.cc:209: Loading symbol saved by previous version v1.0.0. Attempting to upgrade…
[17:26:37] src/nnvm/legacy_json_util.cc:217: Symbol successfully upgraded!
Tuning…
Compile…
WARNING:autotvm:Cannot find config for target=llvm -mcpu=haswell, workload=(‘dense’, (1, 512, ‘float32’), (128, 512, ‘float32’), 0, ‘float32’). A fallback configuration is used, which may bring great performance regression.
Traceback (most recent call last):
File “tune_relay_x86_mobilefacenet.py”, line 217, in
tune_and_evaluate(tuning_option)
File “tune_relay_x86_mobilefacenet.py”, line 198, in tune_and_evaluate
net, target=target, params=params)
File “/home/tx/DL/tvm/python/tvm/relay/build_module.py”, line 284, in build
params)
File “/home/tx/DL/tvm/python/tvm/relay/build_module.py”, line 112, in build
self._build(func, target, target_host)
File “/home/tx/DL/tvm/python/tvm/_ffi/_ctypes/function.py”, line 209, in call
raise get_last_ffi_error()
tvm._ffi.base.TVMError: Traceback (most recent call last):
[bt] (8) /home/tx/DL/tvm/build/libtvm.so(+0xb3ac6e) [0x7feab482ec6e]
[bt] (7) /home/tx/DL/tvm/build/libtvm.so(+0xb377ea) [0x7feab482b7ea]
[bt] (6) /home/tx/DL/tvm/build/libtvm.so(+0xb30b34) [0x7feab4824b34]
[bt] (5) /home/tx/DL/tvm/build/libtvm.so(+0xb38035) [0x7feab482c035]
[bt] (4) /home/tx/DL/tvm/build/libtvm.so(+0xb3ac6e) [0x7feab482ec6e]
[bt] (3) /home/tx/DL/tvm/build/libtvm.so(+0xb377ea) [0x7feab482b7ea]
[bt] (2) /home/tx/DL/tvm/build/libtvm.so(+0xb30b34) [0x7feab4824b34]
[bt] (1) /home/tx/DL/tvm/build/libtvm.so(+0xb3850d) [0x7feab482c50d]
[bt] (0) /home/tx/DL/tvm/build/libtvm.so(+0xfbf67b) [0x7feab4cb367b]
File “/home/tx/DL/tvm/python/tvm/_ffi/_ctypes/function.py”, line 71, in cfun
rv = local_pyfunc(*pyargs)
File “/home/tx/DL/tvm/python/tvm/relay/op/nn/_nn.py”, line 127, in compute_conv2d
inputs[0], inputs[1], strides, padding, dilation, out_dtype=out_dtype)
File “</home/tx/anaconda3/lib/python3.7/site-packages/decorator.py:decorator-gen-28>”, line 2, in depthwise_conv2d_nchw
File “/home/tx/DL/tvm/python/tvm/target.py”, line 372, in dispatch_func
return dispatch_dict[k](*args, **kwargs)
File “</home/tx/anaconda3/lib/python3.7/site-packages/decorator.py:decorator-gen-155>”, line 2, in config_dispatcher
File “/home/tx/DL/tvm/python/tvm/autotvm/task/dispatcher.py”, line 220, in dispatch_func
return dispatch_dict[cfg.template_key](cfg, *args, **kwargs)
KeyError: ‘direct’