
Introduction
The TVM stack has been evolving for more than two years now. The current compiler stack contains several components that were designed at different points in time. This RFC proposes a unified IR infrastructure for the TVM stack by combining past lessons.
From a high-level the proposed infrastructure will consist of:
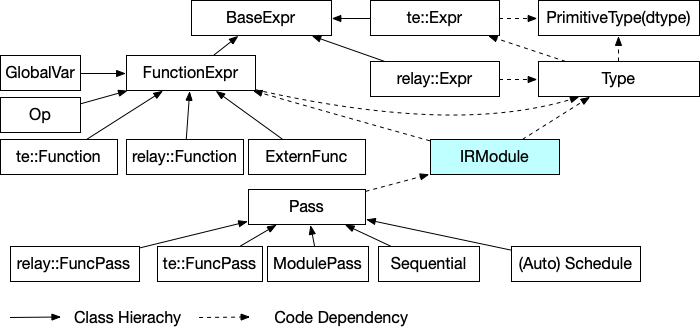
- A unified module, pass and type system for all IR function variants.
- Two major variants of IR expressions and functions: the high-level functional IR(relay)and the tensor-level IR for loop optimizations.
- First-class Python and hybrid script support, and a cross-language in-memory IR structure.
- A unified runtime::Module to enable extensive combination of traditional devices, microcontrollers and NPUs.
Unified IR Module and Pass Infra
The main component of our proposal is to introduce a unified IRModule structure that can contain different variants of functions(relay::Function/te::Function). The namespace te(tensor expression) is a tentative namespace for low-level functions, and comments and suggestions about name choices are more than welcome.
This change will simplify the intermediate representation data structures and terminology used in our previous compilation flow, which can be shown as follows:
importer: model ->
high-level optimizations: relay::Module -> optimizations -> relay::Module ->
low-level optimizations: compute/schedule declaration -> Stmt-> ir passes ->Stmt ->
device-specific codegen: LoweredFunc -> runtime::Module
As shown above, our current flow has different intermediate data structures at different stages (relay::Module, Stmt, LoweredFunc) with different terminologies. Under the new design, we will have a single module structure, and transformations between IRs become ir::Module to ir::Module transformations.

More importantly, we can use specific calling conventions, enabling different function variants to call each other. The following code snippet is a mock-up to demonstrate a module containing both a relay.Function and te.Function. The relay_add_one function can call into the te_add_one function using the destination-passing convention, where outputs are passed as inputs to the function.
def @relay_add_one(%x : Tensor((10,), f32)) {
call_destination_passing @te_add_one(%x, out=%b)
}
def @te_add_one(%a: NDArray, %b: NDArray) {
var %n
%A = decl_buffer(shape=[%n], src=%a)
%B = decl_buffer(shape=[%n], src=%b)
// body ir contents need to be evolved
for %i = 0 to 10 [data_par] {
%B[%i] = %A[%i] + 1.0
}
}
Enabling both high-level functions(relay.Function) and tensor-expression functions to coexist in the same module enables the potential for cross layer optimizations. Of course, most of the transformations will only operate on one type of function and will simply ignore other functions in the same module.
Most importantly, the proposed change will minimize concepts for developers. Developers only need to know about ir::Module and runtime::Module. Every transformation is ir::Module -> ir::Module.
AutoTVM and other schedule transformations can be viewed as an intelligent way to transform an ir::Module. We are exploring ways to embed the current tensor expressions as a special type of Function in ir::Module.
Discussions
One of the design questions is whether to unify the te::Expr and relay::Expr into a single base-class. relay::Expr allows tensor types and supports broadcasting in operations. te::Expr only points to primitive data types(int, float, pointers, buffers). Unifying them into a single base allows reuse of certain AST nodes and potentially mix the expressions. On the other hand, combining two namespaces brings additional complexity of mixing expressions that could be invalid. The separate namespace also allows us to use the low level expression in the tensor types to express shape constraints. Given these considerations, thus we suggest that the two needs to be separated, at least for now. Note that however, both use the same FunctionExpr, to enable calling across different types of functions.
Another design question is how to express shape and data type buffer constraints in the te.Function. One option is to express it as a constraint in the type and make te.Function polymorphic to n. While this approach works well for shape constraints, it is harder to express the sharing of data field for in-place update. The current alternative is to express the constraint via bind expression, we can also make bind information as a part of the function signature, but not as type. This signature is a more faithful representation of the final generated code. This approach allows us to make use of the constraints during analysis. It does introduce less information for shape-related typing checking when a relay function calls into a te.Function. We can resolve that by providing an auxiliary function that reconstructs the function type with constraints.
External Function Interpolation
Besides relay.Function and te.Function, we can also introduce other external function types. As long as we define a clear function calling convention into these modules. For example, we can introduce an ASM function to embed external assembly code. We can also incorporate functions expressed in other IRs such as TorchScript, MLIR and LLVM to make use of these ecosystems.
The only limitation of external function is the ability to do cross-function optimizations (as special code-path has to be written for each external IR). Given most of our use-cases partitions functions in coarse grained matter, we expect that such impact will be low, as long as the major chunk of the code is optimized using the unified in-house variants.
First-class Python and Hybrid Script Support
Python is the most popular language for deep learning frameworks due to its great flexibility and rich ecosystem. We plan to provide first-class python support. This is also a fundamental infrastructure design choice that makes TVM different from other stacks.
Specifically, we expose a programmatic interface which allows developers and researchers to customize compilation, and write new passes in Python. All IR data structures can be created, manipulated and transformed using Python APIs. We will leverage the rich ecosystem of Python ML to further explore ML guided compilation.
Additionally, we plan to specify a subset of python AST that can express every possible function in the TVM IR. The new dialect will be an extension of the current TVM hybrid script, and will serve as a way to construct and inspect the IR in Python. Eventually, it can serve as a secondary text format. In order to cover all the possible IR nodes to enable round trip, we will take a gradual upgrade approach by introducing the meta keyword in the hybrid script similar to the meta support in the current relay text format. The meta is a dictionary of IR nodes that are opaque in the text format but can be populated by json blob. We can always serialize the IR components that are not in the hybrid dialect specification into meta and improve the dialect specifications gradually by adding more native constructs. The code below gives a same function in the hybrid script format.

ML compilation is an open research area, while its great value has already leads to quick transfer to production. We believe these additional flexibilities will increase the rate of innovation, and are critical to help accelerate the wildly open field of deep learning compilation. When the optimization passes become stable, we can seamlessly move passes directly into the C++ core when product ready.
Pave Ways for to Other Languages
Besides the python support, the cross-language runtime object protocol also paves ways for bringing native compiler support into other languages besides python and C++. For example, one possible candidate is rust based the current community interest. We can build language bindings that allows us to write additional compilation passes in rust and expose them to the core tvm compiler. We already provide runtime support on python, rust go, javascript, java.
Extensible Unified Runtime Module
Because TVM stack supports different kinds of compilation targets, we need a unified runtime interface to expose the compiled module to the developer. runtime::Module is an abstract interface for all possible compilation targets. Codegen is defined as a transformation from ir::Module -> runtime::Module. The current runtime module interface already handles the serialization(as shared library) and runtime linking(via PackedFunc).
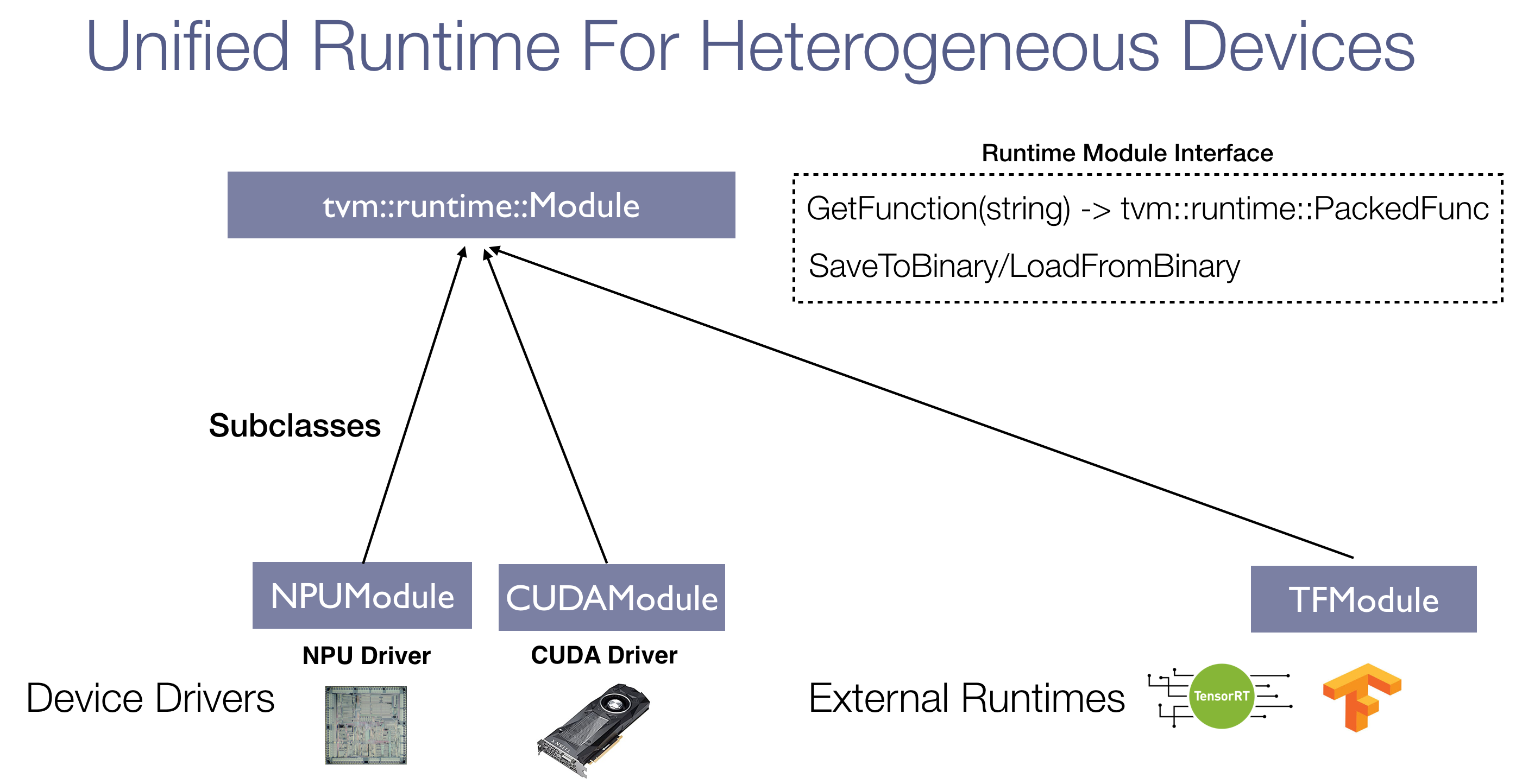
As an artifact of compilation, we will get a module that imports several modules of different types. For example, we could have a graph runtime module that calls into host functions defined on the DSOModule, which then calls into CUDA module to invoke device functions. It is important to create an extensible mechanism to be able to run and export any heterogeneous runtime modules. We have an on-going RFC that proposes a unified exportation format to package all possible runtime::Module into a single shared library.
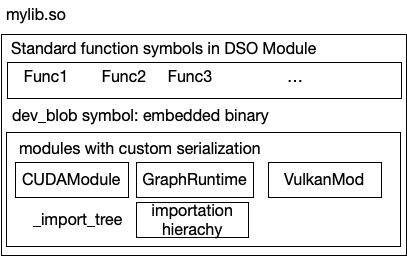
We can also evolve the interface to better handle cases such as hetrogenuous devices and flexible task scheduling.
Discussions
One tension in the runtime design is whether to introduce a more opinionated view of serialization format (e.g. ONNX for model serialization) or allow each module define their own format. We eventually use the later to give more flexibility to each of the module, and only ask each module to expose necessary interface for a unified packaging. Any module packaged in this way will immediately enjoy the benefit by interacting with other components of the stack, including automatic exposure python, java and other runtime APIs, and use of the RPC infrastructure for scalable remote profiling.
Relation with other IRs
Deep learning compilation is an active field and there are other related efforts such as MLIR, LLVM, TorchScript, TensorRT and vendor specific compilation and runtime toolchains.
We believe the most important principle as an open source project is to allow our developers to tap into other ecosystems. In particular, we can incorporate these compilation flow and runtime into tvm by using ExternFunc in the compilation flow, and a specific runtime in the unified runtime interface.
We would also like to facilitate cross IR translations, for example, TorchScript to Relay importer and expose compilation back to a PyTorch compatible function. Another area of interest would be to create translation from MLIR-TF dialect to TVM IR, and make enable MLIR functions as part of ExternFunc support to give better support and interpolation for TF ecosystem.
The scope of TVM’s IR remains very focused – automating the optimization of deep learning workloads on diverse hardware backends and enable our developers to easily integrate the TVM into their stack.
Timeline Upgrade Path
Once we agree on the general design, we can step several refactor steps to bring the current codebase to the new IR infrastructure.
- Introduce ir::Module and ir::Function
- Move relay::Module to make use of ir::Module
- Move the current low-level IR infra ir_pass and LoweredFunc transformations to Module->Module
- Introduce text format and hybrid script specifications of the unified ir::Module
- Continue to evolve the design of the IRs themselves
Please share your comments:)
 borrowing from neuroscience, axon is a fudamental part of relay. I think the name is good because it is related to brain and relay, and it is short, pronounceable.
borrowing from neuroscience, axon is a fudamental part of relay. I think the name is good because it is related to brain and relay, and it is short, pronounceable.